
- 热门阅读



- TAG
-
- 小学生作文选集之钓鱼 jur (1)
- 采访 (1)
- 北京医疗队驰援 (1)
- 空灵 (1)
- 得道 (1)
- 学到 (1)
- 细读 (1)
- 慢跑 (1)
- 1-6 (1)
- Day535 (1)
- 减肥日记 (1)
- 400字 (3)
- 笑嘻嘻 (1)
- 老爸 (2)
- 《美好的回忆》 (2)
- 十二篇 (1)
- 小钩简饵 (1)
- 钓鱼史 (1)
- 硬逼 (1)
- 二流 (1)
- 三流 (1)
- 煎鸡蛋 (1)
- 老鼠 (1)
- 上篇 (1)
- 浓缩 (1)
- 300篇 (1)
- 数篇 (1)
- 体裁 (1)
- 18种 (1)
- 欠缺 (1)
- 汴河 (1)
- 可视 (1)
- 老巷子 (1)
- 北侧 (1)
- 港口 (1)
- 地处 (1)
- 宿州市 (1)
- 江夏庙山 (2)
- 哪方面 (1)
- 墨西哥 (1)
- 京都 (1)
- 扑灭 (1)
- 出警 (1)
- 田地 (1)
- 符离 (1)
- 下河 (1)
- 半个多月 (1)
- 新春开门红 (1)
- 龙河 (1)
- 萧县 (1)
- 斜风细雨 (2)
- 蓑衣 (2)
- 青箬笠 (2)
- 视角 (1)
- 险峰 (1)
- 十里长山 (1)
- 俩个 (2)
- 新汴河 (1)
- 知青 (1)
- 频发 (1)
- 恒泰 (1)
- 大典 (1)
- 祭 (1)
- 地火 (1)
- 宿州网 (1)
- 8月15日 (2)
- 制造 (1)
- 共享电动车 (1)
- 五万 (1)
- 贷款 (1)
- 入会 (1)
- 北京市顺义区海狼钓鱼俱乐部 (1)
- 便 (1)
- 会员费 (1)
- 缴 (1)
- 轻信 (1)
- 粽子 (1)
- 出群 (1)
- 踢 (1)
- 320 (1)
- 半瓶 (1)
- 治水 (1)
- 会员制 (1)
- 辑里村 (2)
- 济南市钓鱼协会 (1)
- 支招 (1)
- 冤家 (1)
- 五、六年 (1)
- 3千元 (1)
- 炒股 (1)
- 难计 (1)
- 花钱买 (1)
- 启示录 (1)
- 号码 (1)
- 鍙戝睍 (1)
- 鍏充簬 (1)
- 涓浗閽撻奔杩愬姩鍗忎細 (1)
- 现金 (1)
- 10月19日 (1)
- 焦岗湖 (1)
系难统难设难计难
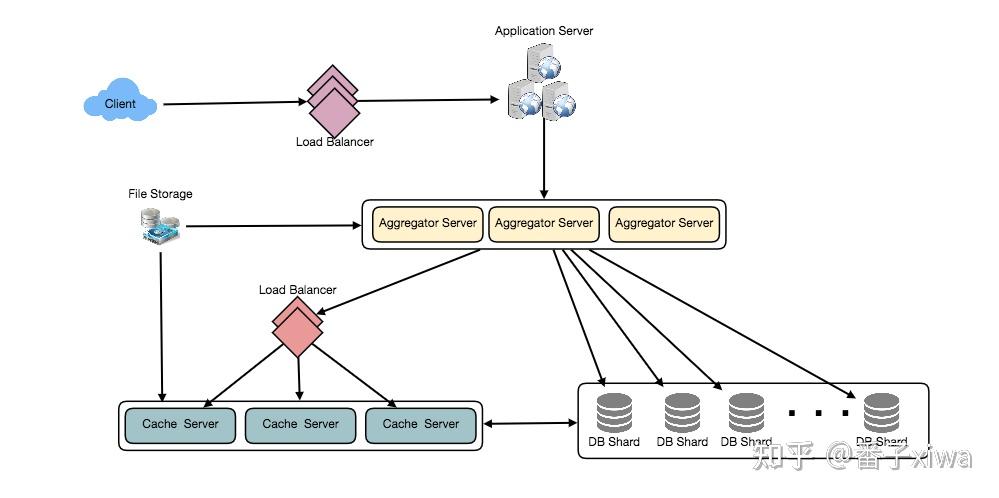
A Beginners Guide to Scaling to 11 Million+ Users on Amazons AWS - High Scalability -
https://www.jyt0532.com/2017/03/27/system-design/
要求、约束(资源)、API、数据库、算法、通信、排序、查找、
下面这个是系统设计
https://wwweducativeio/collect12/5668600916475904下面这个是OOD
https://wwweducativeio/collect24/5636470266134528系统设计基础:
性能:
响应时间(重复请求的方式,然后计算平均响应时间)、
吞吐量(在单位时间内可以处理的请求数量,通常使用每秒的请求数来衡量。)
并发用户数(同时处理的并发用户请求数量。)性能优化:
集群
缓存
异步伸缩性:
向集群中添加服务器来缓解不断上升的用户并发访问压力和不断增长的数据存储需求。
如果系统存在性能问题,那么单个用户的请求总是很慢的;
如果系统存在伸缩性问题,那么单个用户的请求可能会很快,但是在并发数很高的情况下系统会很慢。
应用服务器只要不具有状态,那么就可以很容易地通过负载均衡器向集群中添加新的服务器。
关系型数据库的伸缩性通过 Sharding 来实现,将数据按一定的规则分布到不同的节点上,从而解决单台存储服务器的存储空间限制。
对于非关系型数据库,它们天生就是为海量数据而诞生,对伸缩性的支持特别好。扩展性:
添加新功能时对现有系统的其它应用无影响,这就要求不同应用具备低耦合的特点。使用消息队列进行解耦,应用之间通过消息传递进行通信;使用分布式服务将业务和可复用的服务分离开来,业务使用分布式服务框架调用可复用的服务。新增的产品可以通过调用可复用的服务来实现业务逻辑,对其它产品没有影响。可用:
冗余:
监控:
服务降级:保证高可用的主要手段是使用冗余,当某个服务器故障时就请求其它服务器。应用服务器的冗余比较容易实现,只要保证应用服务器不具有状态,那么某个应用服务器故障时,负载均衡器将该应用服务器原先的用户请求转发到另一个应用服务器上,不会对用户有任何影响。存储服务器的冗余需要使用主从复制来实现,当主服务器故障时,需要提升从服务器为主服务器,这个过程称为切换。监控:
对 CPU、内存、磁盘、网络等系统负载信息进行监控,当某个信息达到一定阈值时通知运维人员,从而在系统发生故障之前及时发现问题。服务降级:
服务降级是系统为了应对大量的请求,主动关闭部分功能,从而保证核心功能可用。安全性:
要求系统在应对各种攻击手段时能够有可靠的应对措施。设计模式:
单例:私有构造函数、一个私有静态变量
在简单工厂中,创建对象的是另一个类,
而在工厂方法中,是由子类来创建对象。
从高层次来看,抽象工厂使用了组合,即 Cilent 组合了 AbstractFactory,而工厂方法模式使用了继承。生成器:封装一个对象的构造过程,并允许按步骤构造。
OOD面试套路
七步曲:
“倾听问题,样本确认,
动口不动手的暴力天然解,
动口也动手的最优解,
路演你的思路,
结构化的编码,
单元测试“SOLID原则:
S - Single-responsiblity principle 单一责任原则 —— 一个类只负责一件事O - Open-closed principle 开发封闭原则 —— 对扩展开放,对修改关闭。L - Liskov substitution principle 里氏替换原则 —— 子类对象必须能够替换掉所有父类对象。I - Interface segregation principle 接口分离原则 —— 不应该强迫客户依赖于它们不用的方法。D - Dependency Inversion Principle 依赖反转原则 ——扩展就是添加新功能的意思,因此该原则要求在添加新功能时不需要修改代码。符合开闭原则最典型的设计模式是装饰者模式,它可以动态地将责任附加到对象上,而不用去修改类的代码。
经典:
抽象。系统设计面试是一个非常重要的话题。你应该清楚如何抽象系统,什么是可见的和不可见的其他组件,以及它背后的逻辑是什么。面向对象编程也是很重要的。数据库。你应该清楚关于像关系数据库这样的基本概念。取决于你的水平(应届生或经验丰富的工程师),了解 NoSQL 可能是一个加分项。网络。你应该能够清楚地解释,当你在浏览器中键入gainlo.co时会发生什么。例如应该清楚 DNS 查找和 HTTP。并发。如果你能够识别系统中的并发问题,并告诉面试官如何解决这个问题,那将是非常棒的。有时候这个话题可能很难,但是需要了解一些基本的概念,比如说竞态条件,死锁是底线。操作系统。有时你与面试官的讨论可能会非常深入,这时最好知道操作系统在底层如何工作。机器学习(可选)。你不需要成为专家,但是一些基本的概念,如特征选择,通常 ML 算法的工作方式,最好熟悉它们。沟通和解决、技术能力和分析能力
自顶向下(层次)和模块化(组件):用户、前端、后端、数据(实体、界面+控制、数据模型、数据库)
推荐系统:收集用户数据(位置、偏好)、离线流水线生成推荐、存储数据并提供给前端
巨大的数据集,离线流水线必须运行大量的数据,那么可能会使用 MapReduce 或 Hadoop。权衡:时间空间。
发展:简单到复杂
面试官真正需要的是如何解决问题的概要想法。使用什么工具并不重要,但是如何定义问题,如何设计解决方案以及如何逐步分析问题是非常重要的。
MVC

你对问题的本质的描述就是Model。解决问题就是给问题建立Model。—— 核心
Controller 和 View 分别是 Model 的 输入 和 输出。
说到底,View 和 Controller 可以是 Model 的一部分。为人么要单独把他们跟 Model 分开呢?因为 View 和 Controller 是外在的东西,只有 Model 是本质的东西。外在的东西天天变化,但很少影响本质。把他们分开比较容易维护。
比如同样是跑 Android 系统的电脑,可以做成手机,可以做成笔记本,还可以做成机顶盒。无非就是 View 换成显示器,液晶屏,还是电视机,Controller 换成触摸屏,键盘,还是遥控器的问题。本质上其实是同一个 Model (Android 电脑)。View :要保存中间的输入状态,要做逻辑验证
逻辑等。
Controller 做的工作都比较简单,无非就是转转格式,做做验证。
——完成从Model到View的转换工作。
甚至有时 View 的工作也很枯燥,比如输出 JSON 或 XML。所有mvx的设计模式都是通过x实现model和view的解耦。在mvc中这个x是control。
面向对象
复杂的问题转化为一组具体的对象,
并确定这些对象之间的相互作用以解决手头的问题。
设计时识别模式,并在适用的情况下有效地应用经过时间考验的解决方案,而不是重新发明轮子。
需求:
用例/功能:
类:
活动图:
存储:
扩展:
设计模式:聚合:表示整体由部分组成,但是整体和部分不是强依赖的,整体不存在了部分还是会存在。
组合:和聚合不同,组合中整体和部分是强依赖的,整体不存在了部分也不存在了。比如公司和部门,公司没了部门就不存在了。但是公司和员工就属于聚合关系了,因为公司没了员工还在。时序图、序列图
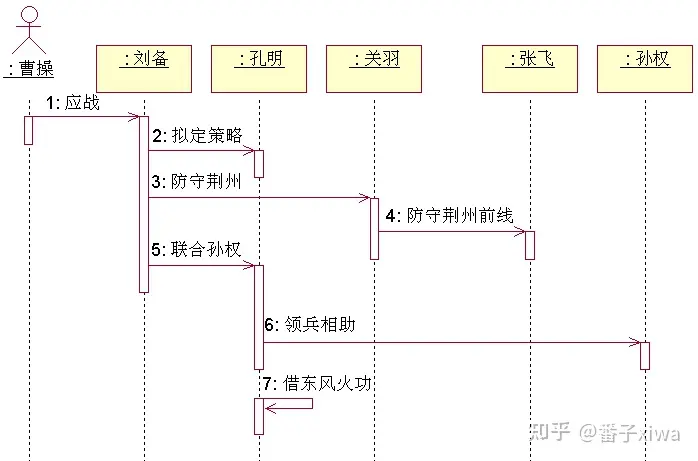
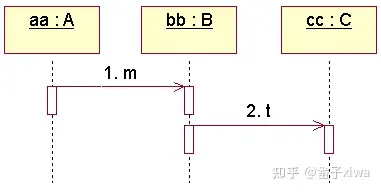
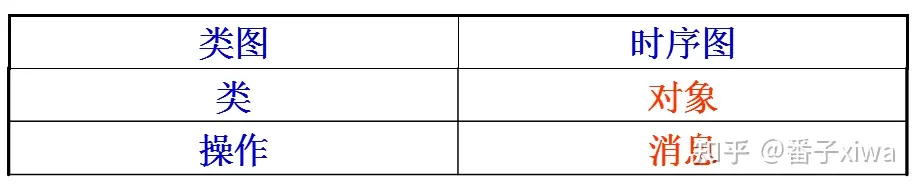
用对象间的交互来描述用例。(注意是对象间的)
寻找类的操作。
注意消息是很多种的
设计航空管理系统:
要求:
客户应该能够搜索给定日期和来源/目的地机场的航班。客户应该能够预订任何定期航班的机票。客户还可以构建多航班行程。该系统的用户可以查看航班时刻表、出发时间、可用座位、到达时间和其他航班详情。客户可以在一个行程中为多名乘客预订。只有系统管理员可以添加新的飞机、航班和航班时刻表。管理员可以取消任何预先安排的航班(将通知所有利益相关者)。客户可以取消他们的预订和行程。该系统应该能够处理飞行员和机组人员的飞行任务。该系统应该能够处理预订付款。每当进行/修改预订或他们的航班有更新时,系统应该能够向客户发送通知。实体:
Admin:负责添加新航班及其时刻表、取消任何航班、维护员工相关工作等。前台人员:可以预订/取消门票。客户:可以查看航班时刻表,预订和取消机票。
游客:飞行员/机组人员:可以查看他们分配的航班和他们的时间表。系统:主要负责发送行程变更、航班状态更新等通知。用例:
搜索航班:搜索航班时刻表以查找适合日期和时间的航班。创建/修改/查看预订:预订机票、取消机票或查看有关航班或机票的详细信息。将座位分配给乘客:将座位分配给带有预订的航班实例的乘客。为预订付款:为预订付款。更新航班时刻表:更改航班时刻表,添加或删除任何航班。分配飞行员和机组人员:将飞行员和机组人员分配到航班。类:
航空公司:为该软件设计的组织的主要部分。它具有“名称”和航空公司代码等属性,可将航空公司与其他航空公司区分开来。机场:每家航空公司在不同的机场运营。每个机场都有一个名称、地址和唯一的代码。飞机:航空公司拥有或租用飞机来执行其航班。每架飞机都有名称、型号、制造年份等属性。飞行:系统的主要实体。每个航班都会有一个航班号、出发和到达机场、分配的飞机等。FlightInstance:每个航班可以有多次出现;每个事件都将被视为我们系统中的一个飞行实例。例如,如果英国航空公司从伦敦飞往东京的航班(航班号:BA212)每周发生两次,则这些事件中的每一次都将在我们的系统中被视为一个单独的航班实例。WeeklySchedule 和 CustomSchedule:航班可以有多个时间表,每个时间表都会创建一个航班实例。FlightReservation:针对航班实例进行预订,并具有唯一的预订编号、乘客列表及其分配的座位、预订状态等属性。行程:一个行程可以有多个航班。FlightSeat:此类将代表分配给特定航班实例的飞机的所有座位。该航班实例的所有预订都将通过该舱位为乘客分配座位。付款:将负责向客户收取款项。通知:该类将负责发送航班预订、航班状态更新等通知。活动图:
预订、取消预订、
设计图书馆管理系统:
场景和需求:图书馆系统协助工作人员管理图书,方便用户借阅
任何图书馆成员都应该能够按书名、作者、主题类别以及出版日期来搜索图书。每本书都有一个唯一的识别号和其他详细信息,包括有助于物理定位该书的机架号。一本书可能有不止一个副本,图书馆成员应该能够签出和保留任何副本。我们将一本书的每个副本称为书项。该系统应该能够检索诸如谁拿走了特定书籍或特定图书馆成员签出的书籍等信息。会员可以借出多少本书应该有一个最大限制 (5)。会员可以保留一本书的天数应该有一个最大限制 (10)。该系统应该能够对逾期归还的书籍收取罚款。会员应该能够预订当前不可用的书籍。系统应该能够在预订的图书可用时以及图书在到期日内未归还时发送通知。每本书和会员卡都有一个唯一的条形码。该系统将能够读取书籍和会员借书证上的条形码。用例:
添加/删除/编辑书籍:添加、删除或修改书籍或书籍项目。搜索目录:按书名、作者、主题或出版日期搜索书籍。注册新帐户/取消会员资格:添加新会员或取消现有会员的会员资格。借书:从图书馆借书。预订书籍:预订当前不可用的书籍。续借一本书:续借一本已借阅的书。还书:将已发给会员的图书退还给图书馆。实体:馆员、用户、系统、图书
类:图书馆、目录、书架、书、书副本、工作人员、用户(书证)、书籍预订队列、书籍借出队列、通知消息
图书馆:为本软件设计的组织的中心部分。它具有诸如“名称”之类的属性以将其与任何其他库区分开来,并具有“地址”之类的属性来描述其位置。书籍:系统的基本构建块。每本书都有 ISBN、标题、主题、出版商等。BookItem:任何一本书都可以有多个副本,每个副本都将被视为我们系统中的一个书项。每本书都有一个唯一的条形码。账户:我们在系统中会有两种账户,一种是普通会员,另一种是图书管理员。借书证:每个图书馆用户都将获得一张借书证,用于在发行或还书时识别用户身份。BookReservation:负责管理书籍项目的预订。BookLending:管理图书物品的借出。目录:目录包含按特定标准排序的书籍列表。我们的系统将支持通过四个目录进行搜索:标题、作者、主题和发布日期。罚款:这个班级将负责计算和收取图书馆会员的罚款。作者:这个类将封装一个书籍作者。架子:书会放在架子上。每个机架将由机架编号标识,并具有位置标识符来描述机架在库中的物理位置。通知:这个类将负责向图书馆成员发送通知。活动图:借书、还书、续借 —— 注意校验相应状态
存储:数据库(表)
扩展:隐私(差分数据库)、并发、移动端、无人化、图书馆安防(珍贵书籍)
设计模式:工程模式
设计 Amazon / Flipkart(一个在线购物平台)
除了基本功能(注册、登录等)之外,面试官还会寻找以下内容:
可发现性:买家将如何发现产品?搜索结果如何?购物车和结帐:用户希望购物车和结帐以某种方式运行。设计将如何遵循这些已知的最佳实践,同时引入创新的结账语义,如一键购买?付款方式:用户可以使用信用卡、礼品卡等方式付款。付款方式将如何与结帐流程配合使用?产品评论和评分:用户何时可以发布评论和评分?如何跟踪有用的评论和降低不太有用的评论的优先级?需求:
用户应该能够添加新产品进行销售。用户应该能够按名称或类别搜索产品。用户可以搜索和查看所有产品,但他们必须成为注册会员才能购买产品。用户应该能够在他们的购物车中添加/删除/修改产品项目。用户可以在购物车中结账和购买商品。用户可以对产品进行评分和添加评论。用户应该能够指定将交付其订单的送货地址。如果订单尚未发货,用户可以取消订单。每当订单或发货状态发生变化时,用户都应该收到通知。用户应该能够通过信用卡或电子银行转账支付。用户应该能够跟踪他们的货物以查看其订单的当前状态。主体:
Admin:主要负责账户管理和新增或修改新的产品类别。客人:所有客人都可以搜索目录,添加/删除购物车,以及成为注册会员。会员:会员可以进行客人可以做的所有活动,此外还可以下订单和添加新产品进行销售。系统:主要负责发送订单通知和发货更新。用例:
添加/更新产品;每当添加或修改产品时,我们都会更新目录。按名称或类别搜索产品。添加/删除购物车中的产品项目。结帐以购买购物车中的产品项目。付款以下订单。添加新的产品类别。向会员发送货件更新通知。类:
账号:系统中有两种注册账号:一种是Admin,负责添加新的产品类别和屏蔽/解锁会员;另一个是可以购买/出售产品的会员。客人:客人可以搜索和查看产品,并将其添加到购物车中。要下订单,他们必须成为注册会员。目录:我们系统的用户可以按名称或类别搜索产品。此类将保留所有产品的索引,以便更快地搜索。ProductCategory:这将封装不同类别的产品,例如书籍、电子产品等。Product:这个类将封装我们系统的用户将要买卖的实体。每个产品都属于一个产品类别。ProductReview:任何注册会员都可以添加关于产品的评论。ShoppingCart:用户将他们打算购买的产品项目添加到购物车中。Item:这个类将封装用户将购买或放入购物车的产品项目。例如,一支钢笔可能是一种产品,如果库存中有 10 支钢笔,则这 10 支钢笔中的每一支都将被视为一个产品项目。Order:这将封装一个购买订单以购买购物车中的所有内容。OrderLog:将跟踪订单的状态,例如未发货、待处理、完成、取消等。ShipmentLog:将跟踪货物的状态,例如待处理、已发货、已交付等。通知:这个类将负责向客户发送通知。付款:该类将封装订单的付款。会员可以通过信用卡或电子银行转账支付。活动图:购物
序列图/时序信息:目录中搜索、添加购物车、结帐、
数据库:
软件工程:
MVC模式
设计模式:
扩展:
设计Stack Overflow:
该网站为其用户提供了一个提问和回答问题的平台,并通过会员资格和积极参与来投票赞成或反对问题和答案。用户可以以类似于wiki的方式编辑问题和答案。
Stack Overflow 的用户可以获得声望点和徽章。例如,一个人在回答“赞成”票时获得 10 分,而对问题的“赞成”票获得 5 分。他们还可以获得徽章以表彰他们的重要贡献。更高的声誉可以让用户解锁新的特权,例如投票、评论甚至编辑其他人的帖子。
需求:
任何非会员(客人)都可以搜索和查看问题。但是,要添加或支持问题,他们必须成为会员。成员应该能够发布新问题。成员应该能够为未决问题添加答案。成员可以对任何问题或答案添加评论。会员可以对问题、答案或评论进行投票。成员可以标记问题、答案或评论,以引起严重问题或版主注意。任何成员都可以在他们的问题中添加赏金以引起注意。会员将因乐于助人而获得徽章。成员可以投票结束一个问题;版主可以关闭或重新打开任何问题。成员可以为他们的问题添加标签。标签是描述问题主题的单词或短语。成员可以投票删除非常偏离主题或质量非常低的问题。版主可以关闭问题或取消删除已删除的问题。系统还应该能够识别问题中最常用的标签。实体:
Admin:主要负责屏蔽或解除屏蔽会员。访客:所有访客都可以搜索和查看问题。成员:成员可以执行客人可以执行的所有活动,此外还可以添加/删除问题、答案和评论。成员可以删除和取消删除他们的问题、答案或评论。版主:除了成员可以执行的所有活动外,版主还可以关闭/删除/取消删除任何问题。系统:主要负责向会员发送通知和分配徽章。用例:
搜索问题。创建一个带有赏金和标签的新问题。添加/修改问题的答案。为问题或答案添加评论。版主可以关闭、删除和取消删除任何问题。类:
问题:这个类是我们系统的核心部分。它具有标题和描述等属性来定义问题。除此之外,我们还将跟踪问题被查看或投票的次数。我们还应该跟踪问题的状态,以及在问题结束时的结束语。答案:任何答案最重要的属性都是文本和观看次数。除此之外,我们还将跟踪答案被投票或标记的次数。我们还应该跟踪问题所有者是否接受了答案。评论:与回答类似,评论将包含文本,以及查看、投票和标记计数。成员可以对问题和答案添加评论。标签:标签将通过它们的名称来识别,并且会有一个用于定义它们的描述字段。我们还将跟踪标签与问题相关联的每日和每周频率。徽章:与标签类似,徽章也有名称和描述。照片:问题或答案可以有照片。赏金:每个成员在提出问题时,都可以设置赏金以引起注意。赏金将具有总声誉和到期日。账号:我们将在系统中有四种类型的账号,访客、会员、管理员和版主。客人可以搜索和查看问题。成员可以通过回答问题和从赏金中提出问题并赢得声誉。通知:该类将负责向成员发送通知并根据其声誉为成员分配徽章。活动图:提问、搜索、回答、评论、赞赏/dis赞赏、
序列图:
前后端
数据库
软件工程
设计模式
MVC扩展
权限、数据安全、隐私、机器学习、语料采集
向外提供API
设计电影票预订系统
面试官会热衷于在您的回答中看到以下几点:
重复:您如何处理实例,例如同一个电影院有多个电影院同时放映不同的电影?还是同一部电影在同一个电影院/大厅的不同时间放映?付款处理:用户购买机票的流程是什么?选择:用户如何选择座位,确保它没有被其他人预订?价格差异:如何考虑折扣定价?例如,对于学生或儿童。要求:
它应该能够列出附属电影院所在的城市。每个电影院可以有多个厅,每个厅一次可以放映一场电影。每部电影将有多个节目。客户应该能够通过电影名称、语言、类型、发行日期和城市名称来搜索电影。一旦客户选择了一部电影,该服务应该显示运行该电影的电影院及其可用的节目。客户应该能够选择特定电影院的节目并预订门票。该服务应向客户展示电影院大厅的座位安排。客户应该能够根据自己的喜好选择多个座位。客户应该能够区分可用座位和已预订座位。每当有新电影以及预订或取消预订时,系统都应该发送通知。我们系统的客户应该能够使用信用卡或现金支付。该系统应确保没有两个客户可以预订同一个座位。客户应该能够在他们的付款中添加折扣券。实体:
管理员:负责添加新电影及其节目、取消任何电影或节目、阻止/取消阻止客户等。FrontDeskOfficer:可以预订/取消门票。客户:可以查看电影时间表、预订和取消门票。客人:所有客人都可以搜索电影,但要预订座位,他们必须成为注册会员。系统:主要负责发送新电影、预订、取消等通知。用例:
搜索电影:按标题、类型、语言、发行日期和城市名称搜索电影。创建/修改/查看预订:要预订电影放映票,取消它或查看有关放映的详细信息。为预订付款:为预订付款。在付款中添加优惠券:在付款中添加折扣券。分配座位:将向客户显示座位图,让他们选择座位进行预订。退款付款:取消后,只要在允许的时间范围内取消,客户将退还付款金额。类:
帐户:管理员将能够添加/删除电影和节目,以及阻止/取消阻止帐户。客户可以搜索电影并预订节目。FrontDeskOffice 可以预订电影节目的门票。访客:访客可以搜索和查看电影说明。要预订演出,他们必须成为注册会员。电影院:为该软件设计的组织的主要部分。它具有诸如“名称”之类的属性,以将其与其他电影院区分开来。CinemaHall:每个电影院将有多个包含多个座位的大厅。城市:每个城市可以有多个电影院。电影:系统的主要实体。电影具有标题、描述、语言、类型、发行日期、城市名称等属性。节目:每部电影可以有很多节目;每场演出都将在电影院大厅播放。CinemaHallSeat:每个影厅都会有很多座位。ShowSeat:每个 ShowSeat 将对应一个电影 Show 和一个 CinemaHallSeat。客户将根据 ShowSeat 进行预订。预订:预订是针对电影节目的,具有唯一预订号、座位数和状态等属性。付款:负责向客户收取款项。通知:将负责向客户发送通知。活动图:注册、预订、取消预订、添加电影、
并发:如何处理并发;这样没有两个用户可以预订同一个座位?
事务级别隔离 —— SQL 数据库中使用事务来避免任何冲突。
—— 读取行,我们会在它们上获得一个写锁,这样它们就不能被其他任何人更新。前后端MVC
数据库
软工
设计模式扩展
设计ATM
面试官希望看到你讨论以下问题:
透支:当自动柜员机没有现金时,你会怎么做?PIN 验证:如果用户多次输入错误的 PIN 怎么办?读卡:如何检测卡是否正确插入?设计航空公司管理系统
行程复杂性:多航班行程如何运作?如何处理同一行程的多名乘客?提醒:如果航班状态发生变化,如何通知客户?外部访问:系统将如何与预订同一航班的其他参与者交互,例如航空公司的前台操作员?设计二十一点(纸牌游戏)
评分:在系统的哪个级别处理评分?这样做的优点和缺点是什么?规则:如果需要的话,有什么样的灵活性来玩稍微不同的房子规则?投注:如何处理投注支出?赔率是如何计算的?二十一点是世界上玩最广泛的赌场游戏。它属于比较纸牌游戏的范畴,通常在几个玩家和一个庄家之间进行。反过来,每个玩家都与庄家竞争,但玩家之间不会互相对抗。在二十一点中,所有玩家和庄家都试图在不超过 21 点的情况下建立一手牌。最接近 21 的手获胜。
需求:
二十一点是用一副或多副标准的 52 张牌来玩的。标准套牌有 4 套 13 个等级。
首先,玩家和庄家是分开处理的。每手牌都有两张牌。庄家有一张暴露的牌(上牌)和一张隐藏的牌(底牌),让玩家无法获得关于游戏状态的不完整信息。玩家的目标是打出比庄家点数多但小于或等于 21 点的手牌。玩家有责任在下注时下注,并拿下额外的牌来完成他们的手牌。庄家会根据一个简单的规则来抓牌:庄家的手牌在 16 点或以下时,他们会抓牌(称为打牌),当庄家的手数为 17 或以上时,他们不会再抓牌(或站拍)。二十一点对每张牌都有不同的点值:
数字卡 (2-10) 具有预期的点值。面牌(Jack、Queen 和 King)都有 10 分。王牌可以算作一分或十一分。因此,一张 A 和一张 10 或面牌的总点数为 21。这两张牌的获胜者被称为“二十一点”。当点数中包括一个算作 11 的 A 时,总和称为软总和;当 ace 计为 1 时,总数称为 hard-total。例如,A+5 可以被认为是软 16 或硬 6。实体:
庄家:主要负责发牌和游戏决议。玩家:下初始赌注,接受或拒绝额外赌注 - 包括保险,并分牌。接受或拒绝提供的解决方案,甚至包括金钱。在击打、双打和站立拍打选项中进行选择。创造手牌:最初玩家和庄家各有两张牌。玩家可以看到两张牌,而玩家只能看到庄家手中的一张牌。下注:要开始游戏,玩家必须下注。玩家玩牌:如果手牌低于 21 点,玩家有三个选择:击中:手牌得到一张额外的牌,这个过程重复。双倍下注:玩家创建一个额外的赌注,并且手牌再获得一张牌,游戏结束。Stands Pat:如果手牌是 21 点或以上,或者玩家选择站立拍,则游戏结束。Resolve Bust:如果一手牌超过 21,则视为失败。庄家出牌:如果手牌总点数为16或以下,庄家将继续获得新牌,并在点数为17或以上时停止发牌。庄家破产:如果庄家的手牌超过 21,则玩家获胜。拥有两张牌共 21 点(“二十一点”)的玩家手牌按 3:2 支付,所有其他手牌按 1:1 支付。判定胜负类:
牌:标准扑克牌的花色和点值从 1 到 11。BlackjackCard:在二十一点中,牌具有不同的面值。例如,杰克、皇后和国王的面值都是 10。A 可以算作 1 或 11。套牌:标准的扑克牌套有 52 张牌和 4 套花色。鞋:包含一组甲板。在赌场中,发牌员的鞋子是一种游戏设备,可以容纳多副扑克牌。手牌:具有一个或两个点值的牌的集合:硬值(当 A 计为 1 时)和软值(当 A 计为 11 时)。玩家:下初始赌注,用赢和输的金额更新赌注。接受或拒绝提供的额外投注 - 包括保险和分手。接受或拒绝提供的解决方案,甚至包括金钱。在命中、双重和站立选项之间进行选择。游戏:这个类封装了基本的游戏顺序。它运行游戏,向玩家提供赌注,将牌从牌盒发到手中,更新游戏状态,收集失败的赌注,支付获胜赌注,分牌,并响应玩家选择的击球、加倍或站牌。活动图:登录、选择游戏、准备、洗牌、抽出三张作为特殊牌?、发牌、玩家身份变化?、加倍?、打牌、状态校验、
极端:全都选择pass?操作是否合法?
用户、游戏(全局状态)
反作弊
酒店管理系统
房间复杂性:系统将如何支持同一家酒店内的不同房间类型?提醒:系统将如何提醒用户他们的入住日期临近?还有哪些其他警报可能有用?定制:用户如何对他们的房间提出特殊要求?将支持什么样的特殊要求?取消/修改:系统将如何处理预订取消(在允许的时间段内)?其他变化呢?将涵盖哪些类型的修改?要求:
系统应支持标准、豪华、家庭套房等不同房型的预订。客人应该能够搜索房间库存并预订任何可用的房间。系统应该能够检索信息,例如谁预订了特定房间,或特定客户预订了哪些房间。该系统应允许客户取消他们的预订 - 如果取消发生在入住日期的 24 小时之前,则向他们提供全额退款。当预订接近入住或退房日期时,系统应该能够发送通知。系统应维护房间内务日志以跟踪所有内务任务。任何客户都应该能够添加客房服务和食品。客户可以要求不同的设施。客户应该能够通过信用卡、支票或现金支付账单。实体:
客人:所有客人都可以搜索可用的房间,也可以进行预订。接待员:主要负责添加和修改房间,创建房间预订,入住和退房客户。保安系统:主要负责发送订房、取消等通知。经理:主要负责新增工人。管家:添加/修改房间的管家记录。服务器:添加/修改房间的客房服务记录。用例:
添加/删除/编辑房间:添加、删除或修改系统中的房间。搜索房间:按类型和可用性搜索房间。注册或注销帐户:添加新会员或取消现有会员的会员资格。预定房间:预定房间。登记入住:让客人登记入住。退房:跟踪预订的结束和房间钥匙的归还。添加房费:将客房服务费添加到客户的帐单中。更新管家日志:添加或更新房间的管家条目。类:
酒店和HotelLocation:我们的系统将支持酒店的多个位置。房间:系统的基本构建块。每个房间都将由房间号唯一标识。每个房间都有房间风格、预订价格等属性。账户:我们将在系统中拥有不同类型的账户:一个是搜索和预订房间的客人,另一个是接待员。客房部将跟踪房间的客房部记录,服务器将处理客房服务。RoomBooking:这个类将负责管理房间的预订。通知:将负责向客人发送通知。RoomHouseKeeping:跟踪房间的所有管家记录。RoomCharge:封装了客人请求的不同类型客房服务的详细信息。发票:包含针对房间的每笔费用的不同发票项目。RoomKey:每个房间都可以分配一张电子钥匙卡。钥匙将带有条形码,并由钥匙 ID 唯一标识。活动图:预订、取消预订、登记入住、
餐厅管理:
餐厅会有不同的分店。每个餐厅分店都会有一份菜单。菜单将有不同的菜单部分,包含不同的菜单项。服务员应该能够为餐桌创建订单并为每个座位添加餐点。每餐可以有多个餐点。每个餐点对应一个菜单项。该系统应该能够检索有关当前可供步入式客户就座的桌子的信息。系统应支持餐桌预订。接待员应该能够按日期/时间搜索可用的桌子并预订一张桌子。该系统应该允许客户取消他们的预订。系统应该能够在预订时间临近时发送通知。客户应该能够通过信用卡、支票或现金支付账单。每个餐厅分店可以有多个餐桌座位安排。实体:
接待员:主要负责添加和修改餐桌及其布局,创建和取消餐桌预订。服务员:接受/修改订单。经理:主要负责新增工人和修改菜单。厨师:查看和处理订单。出纳员:生成支票和处理付款。系统:主要负责发送订桌、取消等通知。
餐厅管理系统:
添加/修改表格:添加、删除或修改系统中的表格。搜索表:搜索可用表进行预订。下订单:在系统中为一张桌子添加一个新订单。更新订单:修改已下订单,包括添加/修改餐食或餐食项目。创建预订:为可用餐桌创建特定日期/时间的餐桌预订。取消预订:取消现有预订。登记入住:让客人登记入住。付款:支付食物的支票。类:
餐厅:这个类代表一个餐厅。每家餐厅都有注册员工。员工是餐厅的一部分,因为如果餐厅变得不活跃,其所有员工将自动停用。分店:任何餐厅都可以有多个分店。每个分支机构都有自己的员工和菜单集。菜单:所有分店都有自己的菜单。MenuSection 和 MenuItem:一个菜单有零个或多个菜单部分。每个菜单部分由零个或多个菜单项组成。Table and TableSeat:系统的基本构建块。每张桌子都有一个唯一的标识符、最大座位容量等。每张桌子都有多个座位。Order:这个类封装了客户下的订单。膳食:每份订单将包括每个餐桌座位的单独膳食。膳食项目:每餐将由对应于菜单项的一个或多个膳食项目组成。账户:我们在系统中会有不同类型的账户,一个是接待员搜索和预定桌子,另一个是服务员在系统中下订单。通知:将负责向客户发送通知。账单:每个餐点包含不同的账单项目。活动:服务员下单、接待员预订、取消预订、
停车场
支付灵活性:客户如何在不同地点(即在每个楼层的客户信息控制台或出口处)和通过不同方式(现金、信用卡、优惠券)进行支付?容量:如何考虑每个地段的停车容量?当很多变得满时会发生什么?车辆类型:如何为不同的停车位类型分配容量——例如摩托车、紧凑型汽车、电动汽车、残障车等?定价:如何处理定价?它应该适应每小时不同的费率。例如,客户必须支付第一小时 4 美元,第二和第三小时 3.5 美元,以及所有剩余时间 2.5 美元。需求:停车场、全局状态、楼层、出入口、车、票据、支付、车位、车类型、电车充电
停车场应该有多个楼层供顾客停车。停车场应有多个出入口。客户可以在入口处领取停车票,并在出境时在出口处支付停车费。客户可以在自动出口面板或停车服务员处支付车票。客户可以通过现金和信用卡支付。客户还应该能够在每层楼的客户信息门户支付停车费。如果客户已经在信息门户支付,他们不必在出口支付。该系统不应允许超过停车场最大容量的车辆。如果停车位已满,系统应该能够在入口面板和一楼的停车位显示板上显示一条消息。每个停车楼层都会有很多停车位。该系统应支持多种类型的停车位,例如紧凑型、大型、残疾人、摩托车等。停车场应该有一些为电动汽车指定的停车位。这些地点应该有一个电子面板,客户可以通过它为他们的车辆付款和充电。该系统应支持汽车、卡车、货车、摩托车等不同类型车辆的停车。每个停车楼层都应有一个展示板,显示每种停车位类型的任何免费停车位。该系统应支持按小时收费的停车收费模式。例如,客户必须为第一小时支付 4 美元,第二和第三小时支付 3.5 美元,其余时间支付 2.5 美元。类:
Admin:主要负责添加和修改停车楼层、停车位、出入口面板、添加/删除停车服务员等。顾客:所有顾客都可以拿到停车罚单并付费。停车服务员:停车服务员可以代客户办理所有活动,并可取现金支付车票。系统:在不同的信息面板上显示消息,以及从停车位分配和移除车辆。用例:
添加/删除/编辑停车楼层:从系统中添加、删除或修改停车楼层。每个楼层都可以有自己的展示板来展示免费停车位。添加/删除/编辑停车位:添加、删除或修改停车楼层上的停车位。添加/删除停车服务员:在系统中添加或删除停车服务员。取票:在进入停车场时为顾客提供新的停车票。扫描票:扫描票以找出总费用。信用卡支付:用信用卡支付门票费用。现金支付:以现金支付停车罚单。添加/修改停车费:允许管理员添加或修改每小时停车费。类别:
ParkingLot:为该软件设计的组织的核心部分。它具有诸如“名称”之类的属性以将其与任何其他停车场区分开来,并具有“地址”以定义其位置。ParkingFloor:停车场将有许多停车楼层。ParkingSpot:每个停车楼层都会有很多停车位。我们的系统将支持不同的停车位:1) 残疾人、2) 紧凑型、3) 大型、4) 摩托车和 5) 电动。帐户:我们将在系统中有两种类型的帐户:一种用于管理员,另一种用于停车服务员。停车票:这个类将封装一张停车票。顾客进入停车场时会取票。车辆:车辆将停放在停车位。我们的系统将支持不同类型的车辆 1) 汽车、2) 卡车、3) 电动、4) 货车和 5) 摩托车。EntrancePanel 和 ExitPanel: EntrancePanel 将打印门票,ExitPanel 将协助支付门票费用。付款:这个班级将负责付款。该系统将支持信用卡和现金交易。ParkingRate:此类将跟踪每小时的停车费率。它将指定每小时的美元金额。例如,对于两小时停车罚单,该类将定义第一小时和第二小时的费用。ParkingDisplayBoard:每个停车楼层都有一个显示板,用于显示每种停车位类型的可用停车位。该课程将负责向客户展示最新的免费停车位可用性。ParkingAttendantPortal:此类将封装服务员可以执行的所有操作,例如扫描票和处理付款。CustomerInfoPortal:这个类将封装客户用来支付停车罚单的信息门户。付款后,信息门户将更新票证以跟踪付款。ElectricPanel:客户将使用电动面板为他们的电动汽车付款和充电。活动图:
支付停车账单的客户:任何客户都可以执行此活动。
设计模式:单例、工厂
设计一个在线股票经济系统
一个好的答案将涵盖以下几点:
监视列表:系统将如何处理用户创建的监视列表以保存/监视特定股票?交易类型:系统如何处理不同的交易类型,例如止损和限价单?将支持哪些类型?股票手数:如果用户多次购买同一股票,系统将如何区分同一股票的不同“手数”以进行报告?报告:系统将如何生成每月、每季度和每年更新的报告?设计汽车租赁系统
候选人应该能够讨论以下问题:
识别:如何在停车场内对每辆车进行唯一识别和定位?费用:系统将如何收取延迟退货的滞纳金?日志:系统如何为每辆车和每个成员维护日志?定制:系统将如何处理会员对路边援助、全额保险和 GPS 等附加服务的请求?设计一个社交网络:FB、Twitter
理想情况下,您的答案应涵盖:
可发现性:用户如何能够搜索其他用户的个人资料?关注:用户如何在不直接连接的情况下关注/取消关注其他用户?组/页面:除了他们自己的用户配置文件之外,成员如何能够创建组和页面?隐私:系统将如何处理具有某些内容的隐私列表仅显示给指定的连接?警报:如何通知用户预先选择的事件?面向对象设计 - 小土刀的面试刷题笔记:
系统架构设计:数据库,并发处理和分布式系统
题目简单:设计XX系统。需要询问系统具体要求:功能流量、可靠性、容错性初步设计面试官提出后续问题:加功能、流量大、一致性、某个机器挂了完善系统设计考核:适应变化的需求、干净优美考虑周到、解释为啥这么实现
1. 需求感,范围感
2. 知识广度,常识
3. 合理清楚的解决方案
4. 权衡取舍01、抽象abstraction、设计对象object、解耦decoupling(层次和接口):
设计一个程序框架,该程序能够实现一些特定的功能。
——比如,如何实现一个音乐播放器,如何设计一个车库管理程序等等。继承/组合/参数化类型:
“Is-A”表示一种继承关系。
“Has-A”表示一种从属关系,这就是组合我们更偏向于“Has-A”的设计模式。因为该模式减少了两个实例之间的相关性。
对于继承的使用,通常情况下我们会定义一个虚基类,由此派生出多个不同的实例类。设计模式:
创建型(Creational).创建型模式与对象的创建相关。
单例、
—— 引入了歌曲管理器实现数据的存储。歌曲管理器在整个程序中应当实例化一次,其他所有关于数据的操作都应该在这个实例上进行。所以,歌曲管理器应该应用单例模式。实现单例模式的关键在于利用静态变量(static variable),通过判断静态变量是否已经初始化判断该类是否已经实例化。此外,还需要把构造函数设为私有函数,通过公共接口getSharedInstance进行调用。
工厂、
—— 当需要生成一系列类似的子类时,可以考虑使用工厂模式。
—— ImgReader-- GIFReader--JPEGReader
—— ImgReaderFactory
builder、
—— 将一个复杂对象构建过程和元素表示分离。
—— 结构型(Structural).结构型模式处理类或者是对象的组合。
适配器、
—— 将一个类的接口转化成为客户希望的另外一个接口。C可以继承A,或者C把A作为自己的成员变量。
桥、
——
composite、
——
Decorator、
—— 动态地给对象添加一些额外职责,通过组合而非继承方式完成。行为型(Behavioral).行为型模式对类或者是对象怎样交互和怎样分配职责进行描述。
观察者、
—— 定义对象之间的依赖关系,当一个对象“状态发生改变的话,所有依赖这个对象的对象都会被通知并且进行更新。
—— 要求观察者提供一个公共接口比如Update()。然后每个观察者实例注册到被观察对象里面去
—— 观察者和被观察之间是采用push还是pull模式完全取决于应用。
状态、
—— 对于实例A,当A的状态改变时,将A可能改变的行为封装成为一个类S(有多少种可能的状态就有多少个S的子类,比如S1,S2,S3等)。当A的状态转换时,在A内部切换S的实例。
—— 从A的用户角度来看,A的接口不变,但A的行为因A的状态改变而改变,这是因为行为的具体实现由S完成。利用面向对象编程原理进行程序设计:
类是一组相似事物的统称,是对他们共性的一种归纳。

对象是类的实例。
封装、继承(集成、组合)、多态(覆盖、重载)
接口:接口是两种不同事物交互时的一个关卡,更是一组标准,定义了交互双方所应该遵循的规则。从程序的角度来看:这种规则就是一组相关的功能点的集合。
举个栗子:目前有一个鼠标类,当某天我们这个鼠标类的对象需要与主机类的对象进行交互时,此时就应该去实现一个叫USB的接口,方可进行交互。对象的属性:固有属性和状态属性。
有限状态机:例如“带锁的门”
原则
先确定时间,搞出能用的,解决需求针对不同时间、不同地点的需求不同迭代增量开发web交互、加不加缓存(降低延迟)机器学习、强化学习需求、功能和实现方法、模块化、迭代优化、数据收集和分析。
指定这个系统提供什么功能处理多少流量、多少数据、延迟重要否(A和C选哪个)
—— ruanyifen—— cap定理-- 一致性C、可用性A、分区容错P
—— C 写操作之后的读操作,必须返回该值。
—— A 只要收到用户的请求,服务器就必须给出回应。多少机器、什么内存抽象画出大的架构,出现的组件画出来,看面试官希望深入讲哪个组件规模化:让你的系统有容错能力,规模化成大公司的系统架构系统设计与分析题 —— 数据库 + 类的设计 + 算法
请你简单说明一下在系统设计中可能涉及的类、属性和方法。
复杂的问题转化为一组具体的对象,并确定这些对象之间的相互作用以解决手头的问题。
在设计时识别模式,并在适用的情况下有效地应用经过时间考验的解决方案,而不是重新发明轮子。在立即有效的解决方案和适应未来变化的解决方案之间找到适当的平衡。
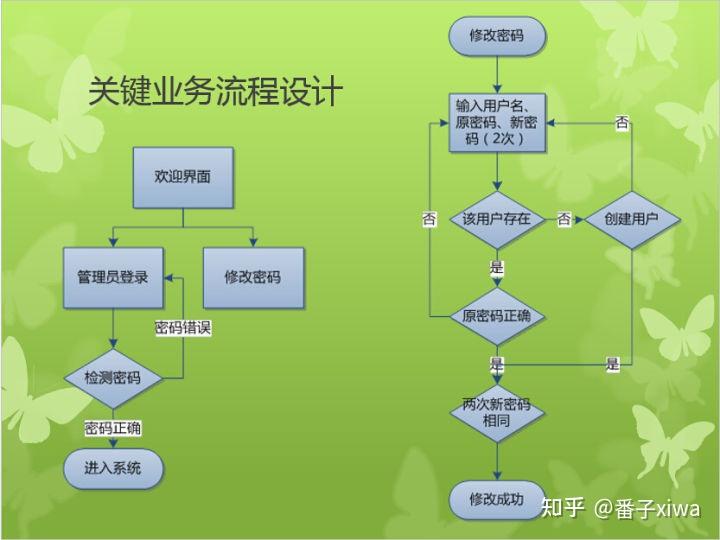
“您是要我演示解决方案的结构,还是要完全实现它?”功能和用例关键对象对象的操作对象的交互教务系统:排课!
数据库:实体、属性、权限、联系、根据设计理论分割表
前端 后端 数据库 MVC:model、view、control
工程:反代理、负载均衡、分布式
安全:SQL脚本注入、XSS攻击、中间人
隐私:差分数据库
排课算法:学生教师老师的时间 —— 优先级、队列、遗传算法
减小问题规模:等价类划分 —— 例如上同样课的学生
讲述原则:冲突(约束条件)!!!
学生、老师、教室、课程的时间不冲突课程数目和教室数目
课程之间的时间间隔。公共课涉及面广、学时多的课程应该优先处理。—— 贪心教室固定。如何检测冲突:图论中的着色(复杂的八皇后问题,回溯)、冲突解决。
甲方思想:
算法:启发式搜索、剪枝
设计图书借阅管理系统:

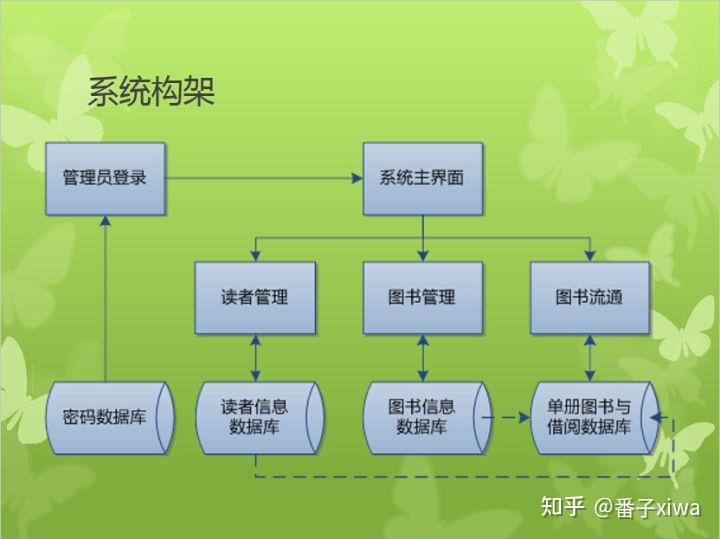
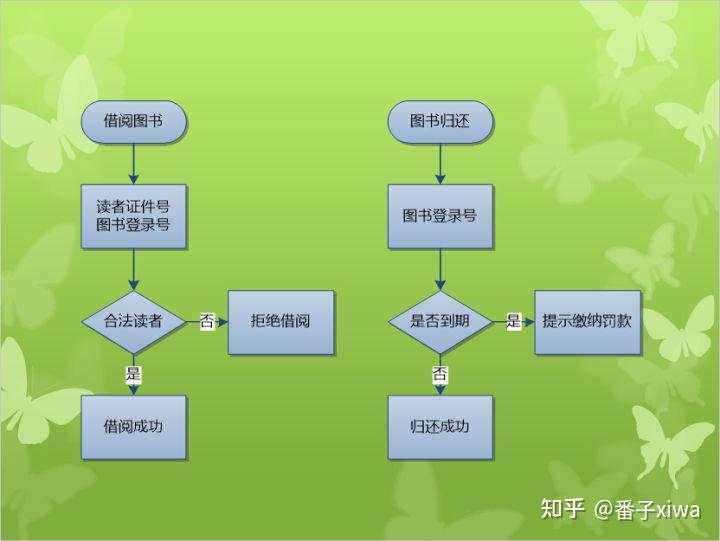
实体:管理员、读者、图书、公告。
界面:管理员界面、读者界面、图书详情、公告、传递请求
控制器:业务逻辑(校验、解析),接受请求、请求数据、界面输出
模型层:操作数据
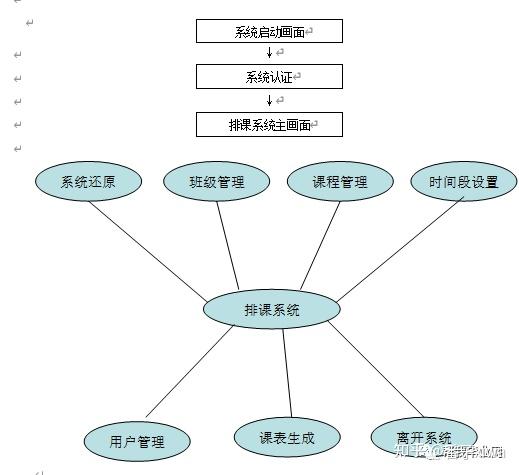
数据库:存储数据设计排课系统
系统设计中需要哪些模块?模块的接口是什么?在该设计中,核心的计算问题是什么?如何实现优化?如何设计算法?这个算法的有什么优势?国外排课问题数学模型的提出是在 60年代,到 70 年代提出了排课表问题从理论上讲是一个NP完全类问题,到 20 世纪 90 年代关于课表问题的研究仍然十分活跃。常用的排课算法有回溯搜索算法、优化决策算法和遗传算法等。
国内对排课问题的研究开始于 80 年代初期,我国的很多大学也普遍开始研究排课系统软件。所用方法包括模拟手工排课的人工智能、时间位图迭加匹配、优先级规划、专家系统等方法。本课题应实现的基本功能如下:
(1)基本信息管理:教师、教室、班级、课程、教学任务等数据的输入,编辑功能;
(2)数据处理:自动排课、课表修改、删除功能;
(3)数据输出:查询教师、教室、班级课程表,报表打印教师、教室、班级课程表。
模块:
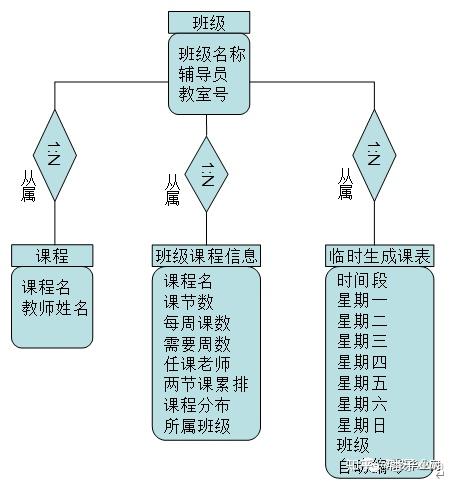
信息输入模块:课程名、时间、地点、老师、学生专业班级、
信息输入错误处理模块:信息输出模块:
信息输出渲染模块数据库:课程信息(代码、名称、类型、考核方式、性质)、教师信息(姓名、代码)、教室(状态、)学生班级、用户登录密码和权限
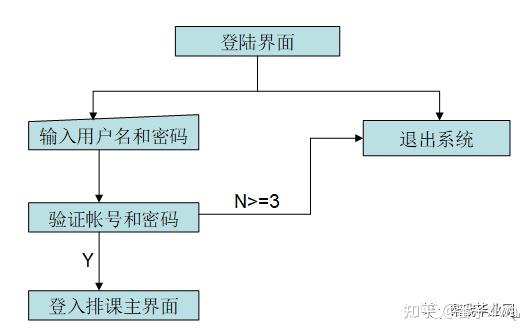
登录验证
多电梯调度
目标:
省电、少等。
电梯状态:当前位置、方向、目的位置、负载、能否到每一层(医院、董事长)、。
事件序列。
距离计算优先级。
方向涉及优先级(饥饿)。用例流程
按钮、
选择电梯、最近的正在向下的、最近的正在向上的,最远的正在向上的、最远的正在向下的
响应队列、
电梯运行到此。
上下班时的算法:
因为需求不同。—— 一楼上去、下到一楼。
优化算法、ML:找规律
强化学习?
电梯随时接受请求,所以很难拿到最优解。
无新的外部请求则可最优化。
实体:楼层、电梯
行为:楼层按钮、电梯按钮位置载重
全局调度策略:初始化、优先级队列、
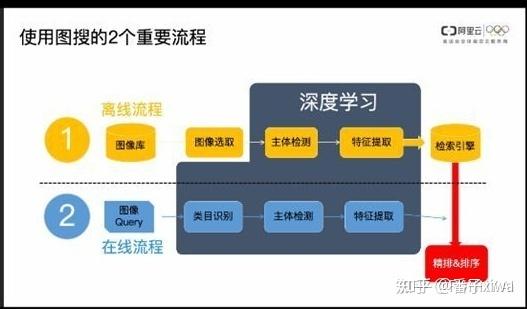
以图搜图APP / 音乐匹配:
问题:
隐私、安全、商业广告滥用、青少年模式
原理、流程:
前端后端
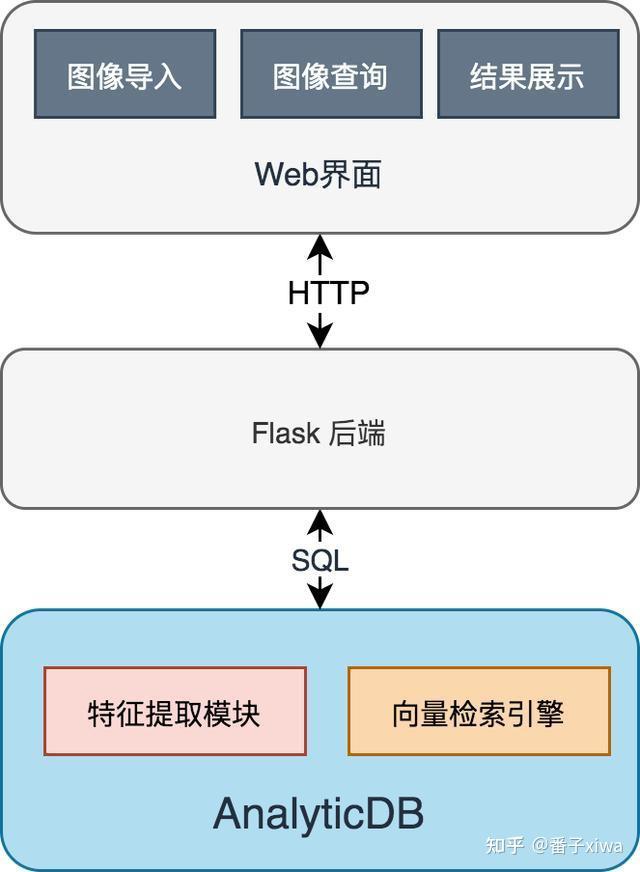
分析型数据库(AnalyticDB)是阿里云上的一种高并发低延时的PB级实时数据仓库
工程(并发、分布式、负载均衡)
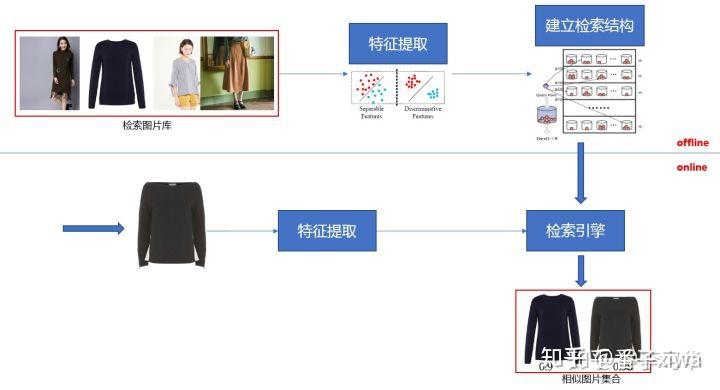
图片库 —— 特征提取 —— 检索结构query —— 特征提取 —— 搜索引擎检索引擎需要应对高并发等一些的工程方面的问题
检索结构更倾向于检索结构算法方面的优化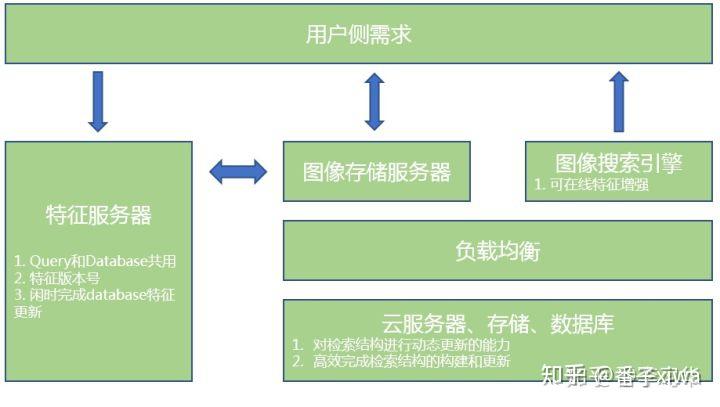
反向代理,负载均衡?
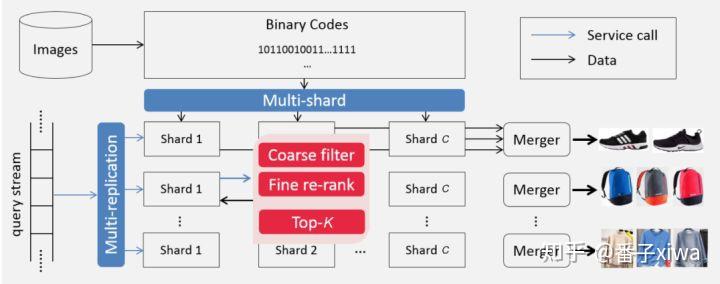
Multi-shards:单机内存无法存储这么多的特征数据,因此特征被存储到多个节点上。对于单次查询,将从每个节点检索出的Top-K结果合并起来,得到最终的结果。
Multi-replications:单个特征数据库无法应对大量的查询流量,特征数据库被复制多份,从而将查询流量分流至不同的服务器集群上,以降低用户的平均查询时间。
离线处理、在线处理:
离线处理主要是指每天生成图像引擎索引的整个过程。具体过程为,首先构建离线图像选品,通过目标检测在选品图像上提取感兴趣的商品,然后对商品进行特征提取,再通过图像特征构建大规模索引库,并放入图像搜索引擎等待查询。执行完成后,以一定频率更新索引库。
在线处理主要是指用户上传查询图片后,对图像的实时处理到返回最终图像列表的在线步骤。与离线处理相似,给定查询图像后,首先预测其具体的商品类目,然后提取图像目标区域的特征,再基于相似性度量在索引引擎中搜索,最后通过重排序返回搜索结果。
用户反馈:
提供备选列表,由用户点击选择,并反馈给系统。
特征、相似度:
特征降维(PCA、DL编码器)、特征标准化(标准差)、特征相似度(距离、cos、杰卡德相似度、)、特征索引和检索(NN,线性对比、聚簇、树)
相似度:
余弦、pic-hash、直方图、SSIM(结构相似度度量:亮度、对比度、结构)、互信息(如果两张图片尺寸相同,还是能在一定程度上表征两张图片的相似性的。但是,大部分情况下图片的尺寸不相同,如果把两张图片尺寸调成相同的话,又会让原来很多的信息丢失,所以很难把握。经过实际验证,此种方法的确很难把握。)目标检测:
停车场,类宽给宽车,窄给窄车:
“您是要我演示解决方案的结构,还是要完全实现它?”
功能和用例:
关键对象:车辆、停车位、停车场、入口、出口、车库运营商
对象的操作:汽车应该能够移动、停在指定地点并持有牌照。停车位应该能够容纳两轮车或四轮车
对象之间的交互:汽车应该能够停在停车位。停车场应该能够容纳多个停车位支付灵活性:客户如何在不同地点(即在每个楼层的客户信息控制台或出口处)和通过不同方式(现金、信用卡、优惠券)进行支付?容量:如何考虑每个地段的停车容量?当很多变得满时会发生什么?车辆类型:如何为不同的停车位类型分配容量——例如摩托车、紧凑型汽车、电动汽车、残障车等?定价:如何处理定价?它应该适应每小时不同的费率。例如,客户必须支付第一小时 4 美元,第二和第三小时 3.5 美元,以及所有剩余时间 2.5 美元。核心需求和功能(属性)、数据结构和算法(优化执行方法)、数据(规律)
car:master_id、size
pos:id、pos、size、state、time、feefit?
收费?
宽窄资源队列?模块:停车、取车、管理
迭代优化,增量式开发
统计数据进行分析需求,优化系统
如何设计一个ATM | OOD 面向对象高频面试题及解析
需求和功能
输入:卡。输出:现金。输入限制(卡)、输入是否合法(吞卡)、输入特点(一张卡可能有多个账户)输出限制(整数钞票)、输出是否合法(ATM钞票存量)对象:信用卡、ATM机器、账户
用例:插卡、登录、选择账户、余额查询、取钱、退出
属性:
方法:类:ATM机器(余额、用户session)、Session(当前的卡、当前账户)、账户(余额、取钱)、
异常现象/意料之外的现象:吞卡了、停电了、网络通信失败了、操作原子性、一致性、
设计模式选择:
组件:
读卡器:读取用户的提款卡。键盘:将信息输入自动柜员机,例如 PIN。牌。屏幕:向用户显示消息。取款机:用于取款。存款槽:供用户存入现金或支票。打印机:用于打印收据。通信/网络基础设施:假设 ATM 具有通信基础设施,可在任何交易或活动时与银行通信。功能:
用户可以拥有两种类型的账户:1) 支票账户和 2) 储蓄账户,并且应该能够在 ATM 上执行以下五种交易:
余额查询:查看每个账户的资金数额。存现金:存现金。存入支票:存入支票。提取现金:从他们的支票账户中提取资金。转移资金:将资金转移到另一个帐户。自动柜员机将由操作员管理,操作员操作自动柜员机并用现金和收据补充。ATM 一次只为一位顾客提供服务,并且在服务期间不应关闭。要在 ATM 中开始交易,用户应插入他们的 ATM 卡,其中将包含他们的帐户信息。然后,用户应输入其个人识别码 (PIN) 进行身份验证。ATM将用户信息发送到银行进行认证;没有身份验证,用户无法执行任何交易/服务。
通过他们的 PIN 识别系统用户。在存入支票的情况下,支票金额不会立即添加到用户帐户中;它需要人工验证和银行批准。假设银行经理可以访问存储在银行数据库中的 ATM 系统信息。假设用户存款不会立即添加到他们的帐户中,因为它将受到银行的验证。在安全性方面,假设 ATM 卡是主要参与者;用户将使用他们的借记卡和安全密码进行身份验证。用例:
运营商:运营商将负责以下操作:
使用指定的钥匙开关打开/关闭自动柜员机。用现金重新填充自动取款机。用收据重新填充 ATM 的打印机。用墨水重新填充 ATM 的打印机。取出存入的现金和支票。客户: ATM客户可以执行以下操作:
余额查询:用户可以查看自己的账户余额。提现:用户可以提现一定数量的现金。存入资金:用户可以存入现金或支票。转账:用户可以向其他账户转账。银行经理:银行经理可以执行以下操作:
生成报告以检查总存款。生成报告以检查总提款。打印总存款/取款报告。检查 ATM 中的剩余现金。类:
ATM:为该软件设计的系统的主要部分。它具有“atmID”等属性以将其与其他可用的 ATM 区分开来,“位置”定义了 ATM 的物理地址。CardReader:封装用于用户认证的ATM读卡器。CashDispenser:封装将分发现金的 ATM 组件。键盘:用户将使用 ATM 的键盘输入他们的 PIN 或金额。屏幕:用户将在屏幕上看到所有消息,他们将通过触摸屏幕选择不同的交易。打印机:打印收据。DepositSlot:用户可以通过存款槽存入支票或现金。银行:封装拥有 ATM 的银行。银行将保存所有账户信息,ATM 将与银行通信以执行客户交易。账户:我们将在系统中拥有两种类型的账户:1)支票账户和 2)储蓄账户。Customer:这个类将封装 ATM 的客户。它将包含客户的基本信息,例如姓名,电子邮件等。卡:封装客户将用来验证自己的 ATM 卡。每个客户可以拥有一张卡。交易:封装客户可以在ATM上执行的所有交易,如BalanceInquiry、Deposit、Withdraw等。活动:身份验证、提现、存支票、转账、
序列图。
前后端
数据库
软件工程
设计模式
软件测试扩展
权衡
数据统计、MLDL、数据安全、隐私
不同场景应该有不同。
设计电梯:浅谈面试中的OOD面向对象设计问题_aoluyi6981的博客-CSDN博客
设计关于一个电梯的class,合理的设计其方法和内部成员?
沟通明确需求。
写出一定会有的类。
题目的需求相对模糊,面试者需要通过不断的沟通和交流来确定题目中可能被遗漏的细节,从而明确需要实现的步骤和细节。
我:这部电梯可承载的人数和重量是多少?装在多高的楼里?
面试官:13人,最大1050kg。20层。
但知道的这些通用属性的数字以后,对你的设计结果帮助是什么呢?无论这部电梯可承载3人还是13人,一共是20层还是40层,其实对设计影响并不大。需不需要考虑超载问题?是否需要设计两种类(客梯 or 货梯)?如果需要,他们之间是什么关系?客梯和货梯能到达的楼层范围是否不一样?这栋楼里当有人按电梯钮时,有多少电梯能响应?当电梯运行时,哪些按钮可以响应?面试官的考察点在于你有没有线条清晰的思路,你们之间的沟通是不是正向的,而不是要你想出所有可能的情况。
类:按钮、请求、控制系统、电梯
联系类之间的关系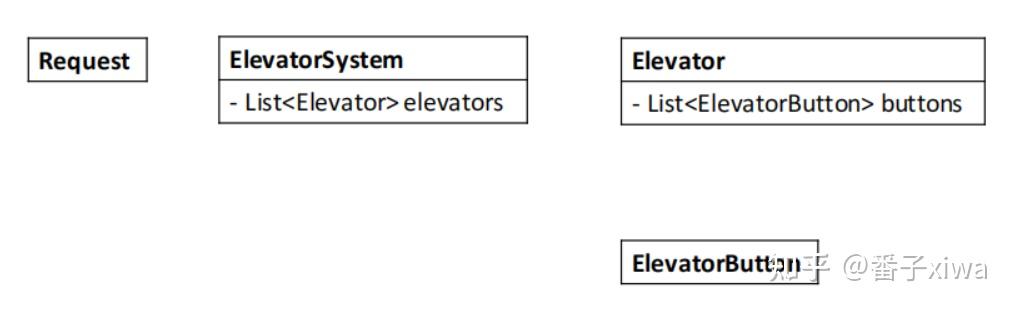
用例、活动图
方法:
开门、关门 —— 门的状态上、下移动 —— 运功方向接受楼层请求—— 当前楼层、当前请求的楼层面向对象的另两个重要特性是继承和多态。
设计电梯这个题目可能并不是特别适合考察这两方面,但是OO设计的思路是大概相似的:分析每一个类的外部方法和内部状态是什么,什么样的方法可以抽象成通用的接口,什么样的类之间存在继承关系等。
调度算法:
流量高峰期、低谷期。
移动端、网页端预约。—— 系统安全、数据安全、用户隐私
紧急情况。—— 火灾、停电、电梯破损、故障
用户权限。—— 特权用户?图书馆管理:
Design a Library Management System - Grokking the Object Oriented Design Interview
系统要求用例图类图活动图代码图书馆管理系统帮助图书馆跟踪图书及其借阅情况,以及会员的订阅和个人资料。
需求:
任何图书馆成员都应该能够按书名、作者、主题类别以及出版日期来搜索图书。每本书都有一个唯一的识别号和其他详细信息,包括有助于物理定位该书的机架号。一本书可能有不止一个副本,图书馆成员应该能够签出和保留任何副本。我们将一本书的每个副本称为书项。该系统应该能够检索诸如谁拿走了特定书籍或特定图书馆成员签出的书籍等信息。会员可以借出多少本书应该有一个最大限制 (5)。会员可以保留一本书的天数应该有一个最大限制 (10)。该系统应该能够对逾期归还的书籍收取罚款。会员应该能够预订当前不可用的书籍。系统应该能够在预订的图书可用时以及图书在到期日内未归还时发送通知。每本书和会员卡都有一个唯一的条形码。该系统将能够读取书籍和会员借书证上的条形码。对象:馆员、会员、系统。
用例:
添加/删除/编辑书籍:添加、删除或修改书籍或书籍项目。搜索目录:按书名、作者、主题或出版日期搜索书籍。注册新帐户/取消会员资格:添加新会员或取消现有会员的会员资格。借书:从图书馆借书。预订书籍:预订当前不可用的书籍。续借一本书:续借一本已借阅的书。还书:将已发给会员的图书退还给图书馆。类:
图书馆: 为本软件设计的组织的中心部分。它具有诸如“名称”之类的属性以将其与任何其他库区分开来,并具有“地址”之类的属性来描述其位置。书籍:系统的基本构建块。每本书都有 ISBN、标题、主题、出版商等。BookItem:任何一本书都可以有多个副本,每个副本都将被视为我们系统中的一个书项。每本书都有一个唯一的条形码。
账户:我们在系统中会有两种账户,一种是普通会员,另一种是图书管理员。
借书证:每个图书馆用户都将获得一张借书证,用于在发行或还书时识别用户身份。BookReservation:负责管理书籍项目的预订。BookLending:管理图书物品的借出。
目录:目录包含按特定标准排序的书籍列表。我们的系统将支持通过四个目录进行搜索:标题、作者、主题和发布日期。罚款:这个班级将负责计算和收取图书馆会员的罚款。作者:这个类将封装一个书籍作者。架子:书会放在架子上。每个机架将由机架编号标识,并具有位置标识符来描述机架在库中的物理位置。通知:这个类将负责向图书馆成员发送通知。活动图:
还书:任何图书馆成员或图书管理员都可以执行此活动。会员逾期归还图书,系统将向会员收取罚款。以下是还书的步骤:续书:在续书(再发行)时,系统会检查是否有其他会员没有预订过同一本书,这样该书就不能续书了。以下是更新书籍的不同步骤:代码:
设计模式:
流量、数据、
部署:数据库、池化、并发、分布式、大数据
机器:数目、存储
性能:CAP、权衡
用户隐私、数据安全
机器学习进行数据挖掘
可视化数据、报表分析
移动端、网页端(SQL注入、XSS脚本、中间人)
设计一个停车场:
Design a Parking Lot - Grokking the Object Oriented Design Interview
要求:
停车场应该有多个楼层供顾客停车。停车场应有多个出入口。客户可以在入口处领取停车票,并在出境时在出口处支付停车费。客户可以在自动出口面板或停车服务员处支付车票。客户可以通过现金和信用卡支付。客户还应该能够在每层楼的客户信息门户支付停车费。如果客户已经在信息门户支付,他们不必在出口支付。该系统不应允许超过停车场最大容量的车辆。如果停车位已满,系统应该能够在入口面板和一楼的停车位显示板上显示一条消息。每个停车楼层都会有很多停车位。该系统应支持多种类型的停车位,例如紧凑型、大型、残疾人、摩托车等。停车场应该有一些为电动汽车指定的停车位。这些地点应该有一个电子面板,客户可以通过它为他们的车辆付款和充电。该系统应支持汽车、卡车、货车、摩托车等不同类型车辆的停车。每个停车楼层都应有一个展示板,显示每种停车位类型的任何免费停车位。该系统应支持按小时收费的停车收费模式。例如,客户必须为第一小时支付 4 美元,第二和第三小时支付 3.5 美元,其余时间支付 2.5 美元。对象:
Admin:主要负责添加和修改停车楼层、停车位、出入口面板、添加/删除停车服务员等。顾客:所有顾客都可以拿到停车罚单并付费。停车服务员:停车服务员可以代客户办理所有活动,并可取现金支付车票。系统:在不同的信息面板上显示消息,以及从停车位分配和移除车辆。用例:
添加/删除/编辑停车楼层:从系统中添加、删除或修改停车楼层。每个楼层都可以有自己的展示板来展示免费停车位。添加/删除/编辑停车位:添加、删除或修改停车楼层上的停车位。添加/删除停车服务员:在系统中添加或删除停车服务员。取票: 在进入停车场时为顾客提供新的停车票。扫描票:扫描票以找出总费用。信用卡支付:用信用卡支付门票费用。现金支付:以现金支付停车罚单。添加/修改停车费:允许管理员添加或修改每小时停车费。类:
ParkingLot: 为该软件设计的组织的核心部分。它具有诸如“名称”之类的属性以将其与任何其他停车场区分开来,并具有“地址”以定义其位置。ParkingFloor:停车场将有许多停车楼层。ParkingSpot:每个停车楼层都会有很多停车位。我们的系统将支持不同的停车位:1) 残疾人、2) 紧凑型、3) 大型、4) 摩托车和 5) 电动。帐户:我们将在系统中有两种类型的帐户:一种用于管理员,另一种用于停车服务员。停车票:这个类将封装一张停车票。顾客进入停车场时会取票。车辆:车辆将停放在停车位。我们的系统将支持不同类型的车辆 1) 汽车、2) 卡车、3) 电动、4) 货车和 5) 摩托车。EntrancePanel 和 ExitPanel: EntrancePanel 将打印门票,ExitPanel 将协助支付门票费用。付款:这个班级将负责付款。该系统将支持信用卡和现金交易。ParkingRate:此类将跟踪每小时的停车费率。它将指定每小时的美元金额。例如,对于两小时停车罚单,该类将定义第一小时和第二小时的费用。ParkingDisplayBoard:每个停车楼层都有一个显示板,用于显示每种停车位类型的可用停车位。该课程将负责向客户展示最新的免费停车位可用性。ParkingAttendantPortal:此类将封装服务员可以执行的所有操作,例如扫描票和处理付款。CustomerInfoPortal:这个类将封装客户用来支付停车罚单的信息门户。付款后,信息门户将更新票证以跟踪付款。ElectricPanel:客户将使用电动面板为他们的电动汽车付款和充电。活动图:
支付停车账单进行停车取车异常/出乎意料:我支付了但是没停、尾随报警、监控
数据分析、数据挖掘
数据安全、用户隐私
移动端预订车位带来的并发、一致性
自动售货机
https://blog.didispace.com/21-object-oriented-and-system-design-problems-to-p/
码的设计(设计文档),编码(代码)以及单元测试(测试)
封装(Encapsulation),多态(Polymorphism)或者继承(Inheritance),
使用抽象类和接口的细节通常这种问题,还会给你一个使用设计模式的机会,因为在这个问题中你可以使用工厂模式去创建不同的售货机。
于设计金融系统,必须要求它们在所有情况下都应按预期工作。所以不管它的断电 ATM 是否应该保持正确的状态(事务),考虑锁定、事务、错误条件、边界条件等,即使你不能提出精确的设计但如果你能够指出非功能性要求,提出一些问题,想想边界条件会有好的进展。
通常来说,需求部分都是不明确的,你需要通过阅读你的问题的陈述来理解事件的你的需求。一些需求是很隐蔽式的。—— 当无法找零时。
售货机。它定义了售货机的所有公用API,通常所有的高级功能都应该在这个类里面。
自动售货机工厂。这是一个工厂类,使用创建不同的售货机。
物品余额
硬币余额
售罄状态。
补货。怎么确认补货正常?
控制系统。异常:断电、操作中断。故障自检。
数据、数据模型、控制层、显示层。
是否联网:数据安全、网络通信失败、
恶意操作:硬币钓鱼、恶意请求、Dos攻击会不会缓存溢出
东西卡住了怎么办——客户服务。
嵌入式系统,内存泄露会非常危险。
变量的范围。
你如何设计交通控制系统?
经典系统设计问题仍然提及频率。 确保你知道如何从一种状态过渡到另一种状态,例如从红色过渡到绿色,从绿色过渡到橙色再过渡到红色等。
—— 有限状态机,且不能冲突
—— 交通流量。采集、数据分析。—— 时间(峰谷)空间(车道)
—— 安全、可靠、停电时、设备故障时。
推特:
需求:发布/搜索/评价文章、关注用户、用户时间线、文章包含图片和视频、前端/后端?、热门话题展示、推送
定义接口:实现需求
资源:扩展、分区、负载均衡以及缓存等。流量规模、存储、带宽?
数据模型:数据在系统的多个组件内的传递方式。
—— 最好先从SQL开始,不行再NoSQL上层设计:系统的核心组件、副本数据备份、分布式存储系统
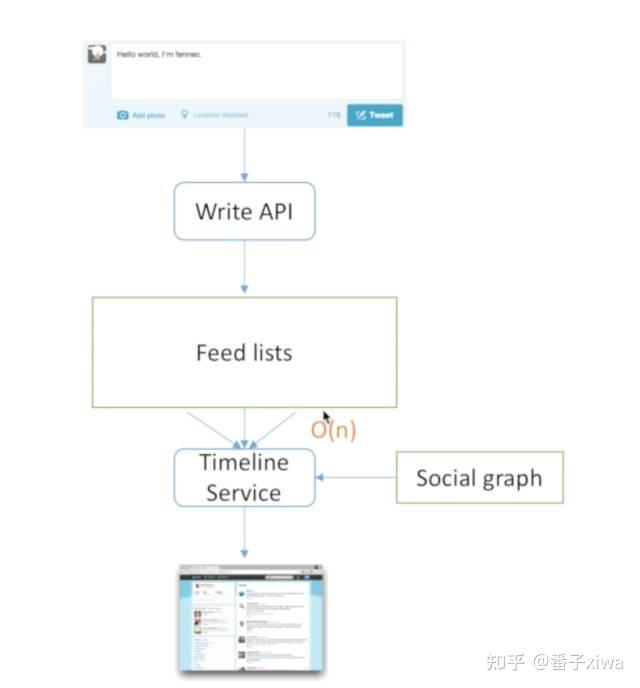
瓶颈:
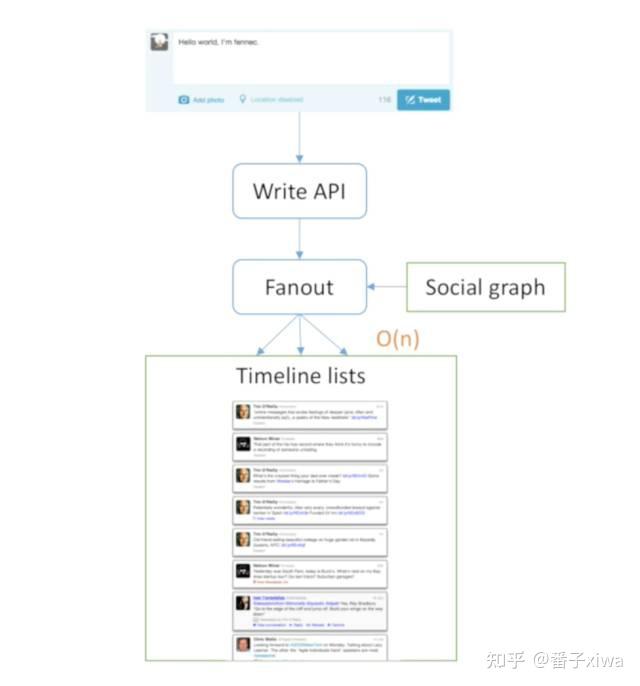
想一想Twitter的本质是什么,它其实是feed流。那什么是feed流呢?有很多list,这些List的集合就是你最终展现的结果,把一些list集合到一块去就是feed流。这个概念跟Kafka其实是非常相似的,Kafka是按照时间排序把很多log流聚合到一块。
在Twitter中,我们有三个feed list,这里需要强调,因为在不同公司不同项目叫法不太一致,我们讲的feed是指单独的list,而list的集合叫timeline。
每个单独的列表是自己的list,例如朋友圈有自己发的内容,你妈妈发的内容,你爸爸发的内容,那三个聚集到一块,成为你观看所有好友list的朋友圈就是timeline。
限制条件:实时的限制、读写的限制、并发
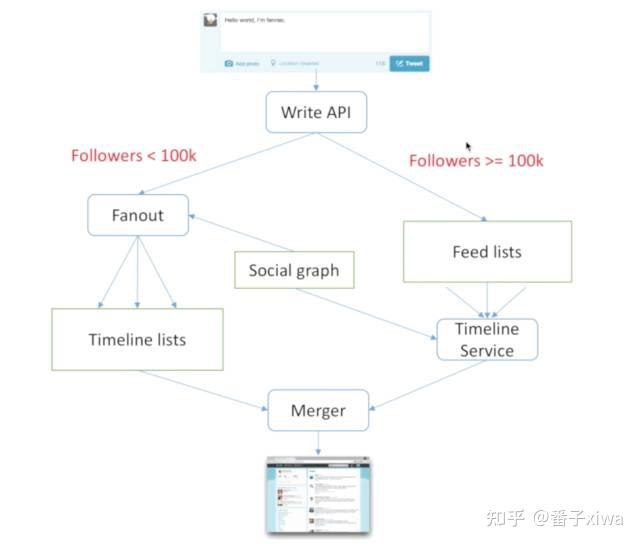
通知:推拉
—— 一种是自己拿广播通知所有人,这叫“推”模式;
—— 一种是有人主动来找你要,这叫“拉”模式。推模式
写的时候是O(n),读的时候是O(1)。
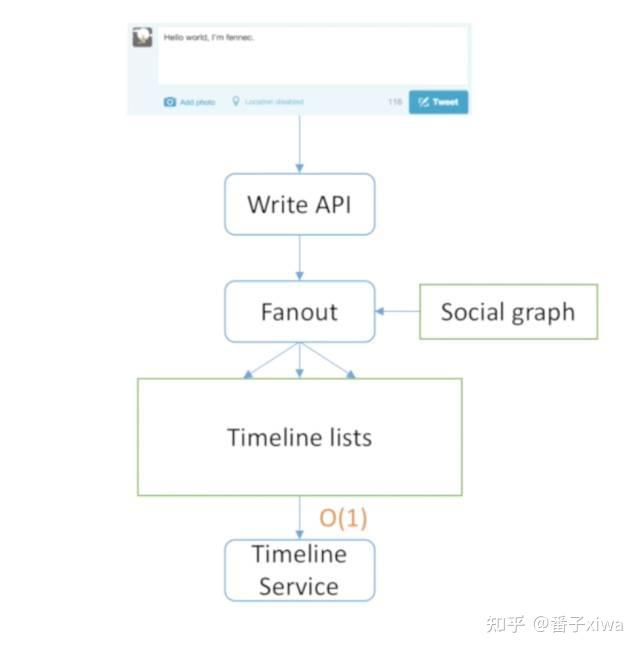
最大缺点就是Lady Gaga模式。Lady Gaga发一条消息时,需要读出5000万个关注者,然后写出5000万份,那在这一瞬间就只能写Lady Gaga的,别人的没法写。
只通知在线用户,因为在线用户需要立刻观看,不在线用户可以慢一些,所以可以用这种方法来优化。
但是广播模式最大的问题仍然是当一个人有很多关注者就会变得很慢。
换成拉:
首先写条消息,然后发到writeAPI,这回变聪明了,这条消息只写到自己的list中,如果是Fannnec就写到Fannec List里面,如果是Lady Gaga就写到Lady Gaga的List里。所以写的时候只写一条,因为只写自己,不写其他人,是O(1)的复杂度。
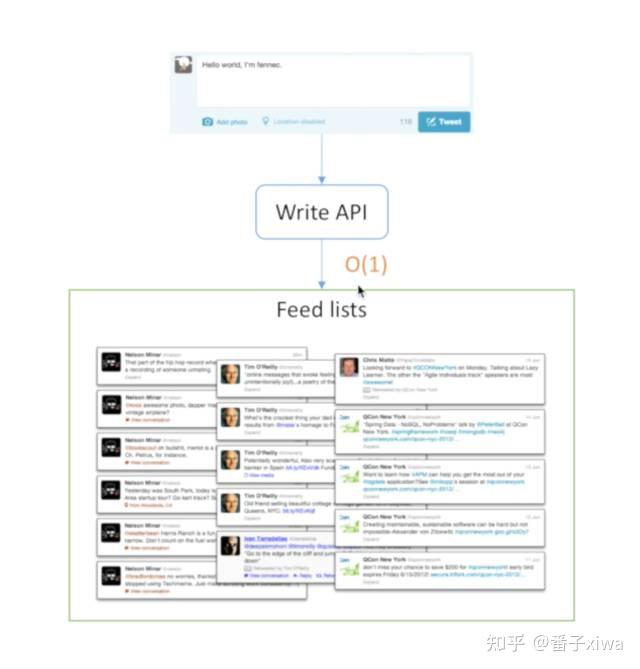
推拉结合:根据用户量设置阈值。
僵尸粉清理。
读写二兄弟,
推拉两姐妹,
选对一个人,
相爱到天黑。推特:
热门话题:主体候选、排名指标
关注推荐:
搜索:存储和排序
数据驱动:
推特:搜索
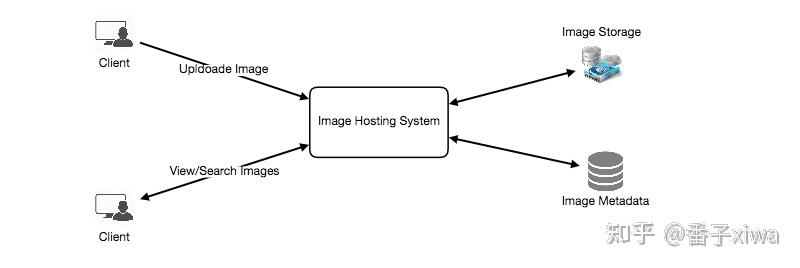
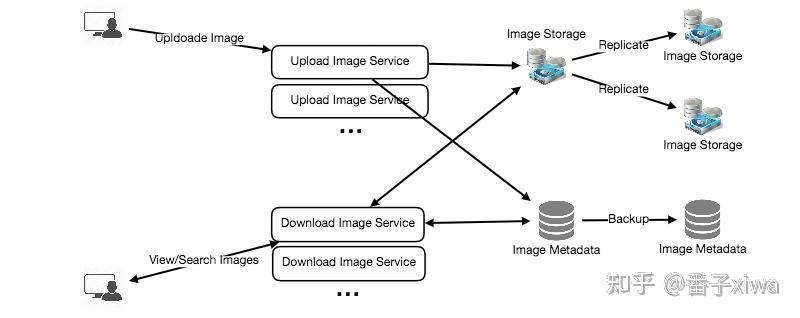
建议先从概要解决方案开始,然后再深入研究各种细节。这种方法的优点是,你能清楚你想要解决什么问题,而且面试官不太可能困惑。
信息流排名:例如,结合时间和用户喜欢这张照片的可能性的算法。
一个常用的策略是提出一个评分机制,将各种特征作为指标并计算每张图片的最终分数。——回归预测
图像通常很大,很少更新。所以独立的图像存储系统有很多优点。
应该压缩图像。一种常用的方法是仅存储/提供压缩版本的图像。Youtube
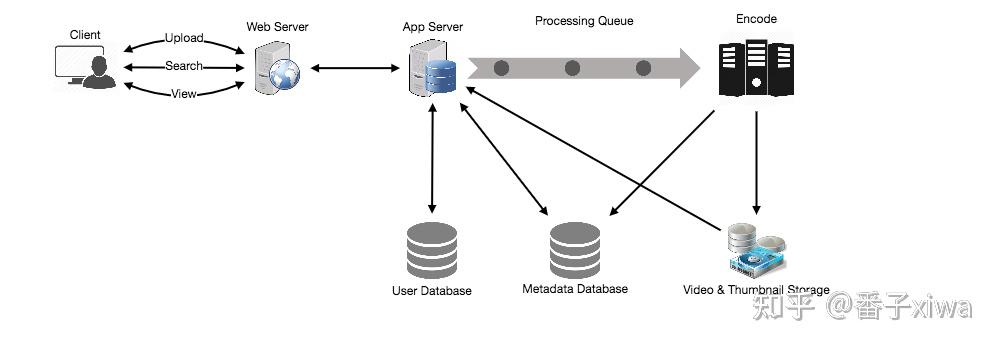
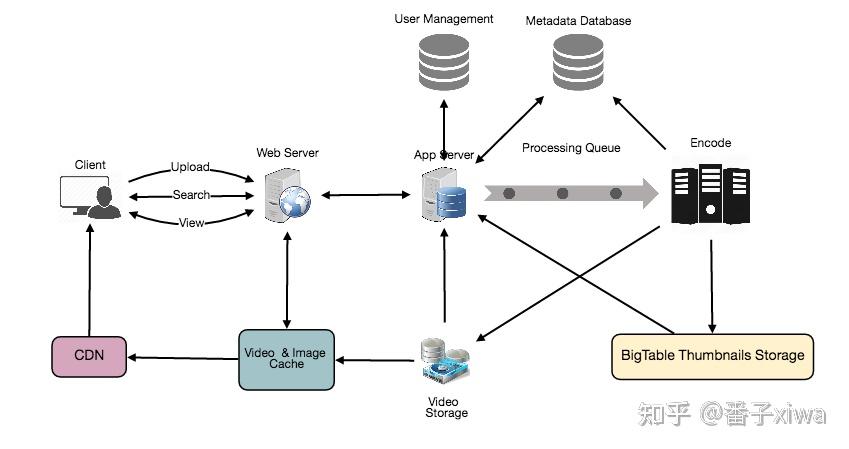
FB 新闻
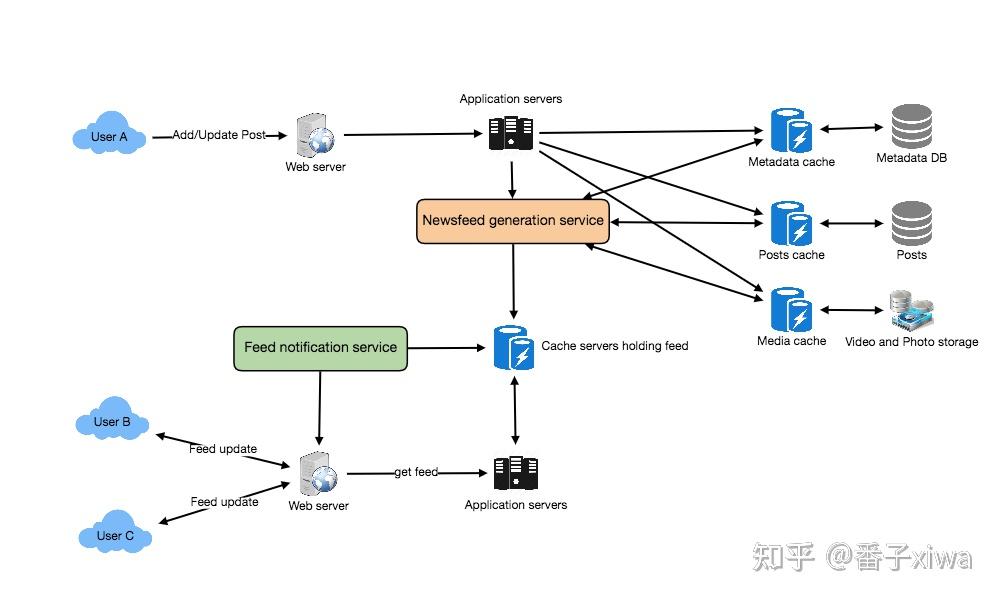
生产者、管理者、消费者
存储、缓存、推送、搜索
爬虫:
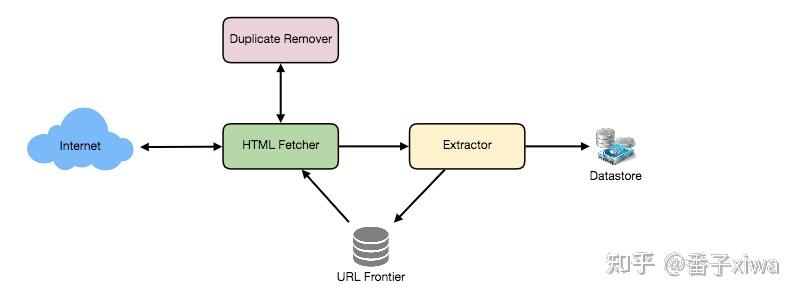
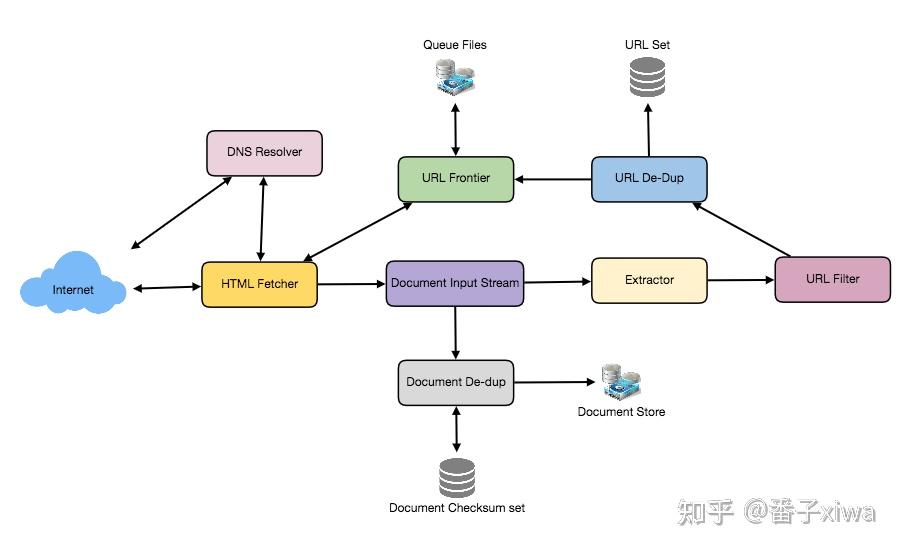
TinyURL:URL缩短服务是用来为长URL创建简短别名
短网址在显示、打印、发送消息或微博时能够节省大量空间。另外,用户输错短网址的可能性也比较小。
功能性需求:唯一性、重定向、过期时间
非功能性需求:可用性、延迟
扩展需求:统计、REST API资源估计:流量、内存、存储、带宽
系统API:
数据库设计:SQL/NoSQL、记录数目、对象大小、IO高频?
缓存、负载均衡、安全和权限
使用的具体技术并不重要。真正重要的是如何解决这个问题的概要思想。这就是我不提 Redis,RebornDB 等东西的原因。
谷歌文档:同时编辑
当问题很大时,建议提供概要解决方案。抽象解决方案的一种方法是,将大系统分成更小的组件。
文件存储。由于 Google 文档是 Google 云端硬盘的一部分,因此我也包含了存储功能。该系统允许用户将文件(文档)分组到文件夹,并支持编辑/创建/删除等功能。它像一个操作系统。在线编辑和格式化。毫无疑问,Google 文档的核心功能之一就是在线编辑。它支持几乎所有的微软 Office 操作,也许更多。合作。 Google Docs 允许多个人同时编辑单个文档,这真是太神奇了。这肯定是一个技术挑战。访问控制。你可以与你的朋友分享文档,并给予不同的权限(所有者,只读,允许评论等)。存储和格式化在一定程度上可以看作是后端和前端。
Google Docs(或 Google Drive)的存储系统非常接近操作系统。它有像文件夹,文件,所有者等概念。因此,构建这样的系统,基本积木是一个文件对象,它包含内容,父项,所有者以及其他元数据,如创建日期。父项代表文件夹关系,根目录的父项为空。
如何使用相应格式储存文档。如果你了解 Markdown,那绝对是最好的解决方案之一。并发:
你不能只让每个人自己工作,然后合并每个人的副本或选取最后一次编辑。如果你已经尝试了协作编辑功能,你实际上可以看到对方正在做什么,并获得即时反馈。
首先,让我们考虑最简单的情况 - 只有两个人在编辑同一个文档。
服务器可以为每个人保留量份相同的文档,并跟踪完整的修订历史。
当 A 通过在开头添加x来编辑文档时,这个改变将与 A 所看到的最后修订一起发送到服务器。
假设此时 B 删除最后一个字符c,并且这个改变也是这样发送到服务器。操作转换(Operational Tranformation)。
如果你从没听说也没关系,基本思想是根据修改和其他合作者的修改来转换每个人的改动。权限/访问控制:
对于每个文件,你可以维护一个合作者列表,带有相应权限如只读,所有者等。当一个人想做特定的行动,系统检查他的权限。
速度。当所有者更新文件夹的权限(例如删除特定的查看者)时,应将此更新传播给其所有子项。速度可能是一个问题。一致性。当有多个副本时,保持每个副本的一致性尤其重要,特别是当多个人同时更新权限时。传播。可能有很多传播情况。除了更新文件夹的权限应该反映在所有的子文件之外,如果你向某人授予文档 D 的读取权限,那么他也可能已经拥有了文档 D 的所有父文件夹的读取权限。如果有人删除了 D 文件,我们可能会撤销 D 的父文件夹的阅读权限(也许不是,这更像是产品决策)。推送:
当用户进入他们的主页时,他们会以特定的顺序看到好友的更新。推送可以包含图片,视频或文本,用户可能拥有大量的好友。
数据模型。我们需要一些模型来存储用户和推送对象。更重要的是,当我们试图优化系统的读/写时,有很多的权衡。接下来我会详细解释推送排名。 Facebook 的排名不仅仅按照时间顺序排列。推送发布。当只有几百个用户时,发布可能是微不足道的。但是,如果有数百万甚至数十亿的用户,这可能开销较大。所以这里有一个规模问题。数据模型:
有两个基本对象:用户和推文。对于用户对象,我们可以存储用户 ID,名称,注册日期等等。对于推文对象,有推文 ID,推文类型,内容,元数据等,它们也应该支持图片和视频。
如果我们使用关系数据库,我们还需要建立两个关系:用户与推文的关系和好友关系。
创建一个用户-推文表,存储用户 ID 和相应的推文 ID。对于单个用户,如果他已经发布了多个推文,则可以包含多个条目。
好友关系,邻接表是最常见的方法之一。一个常见的优化是将推文内容和推文 ID 一起存储在用户-推文中,这样我们就不需要再连接推文了。这种方法被称为去规范化,这意味着通过添加冗余数据,我们可以优化读取性能(减少连接数量)。
缺点是显而易见的:
数据冗余。我们正在存储冗余数据,占用存储空间(经典的时空关系)。数据一致性。每当我们更新推文时,我们需要更新推文表和用户-推文表。否则,数据不一致。这增加了系统的复杂性。Facebook 上的排名实际上的工作方式 - EdgeRank。亲密度,边权重和时间衰减。
亲密度:距离——评论,标签,分享,点击等显式交互是我们应该使用的强有力的信号。
将活动推给所有好友或粉丝的过程称为扇出。所以推送方式也被称为写时扇出,而拉入方式则是加载时扇出。
如果遵循 80-20 规则,则 80% 的成本来自 20% 的功能/用户。因此,优化确实涉及瓶颈的确定。
聊天:
构建消息应用最常用的方法之一,就是拥有一个聊天服务器,作为整个系统的核心。消息到达时,不会直接发送给接收者。相反,它会转给聊天服务器并先存储在那里。然后,根据接收者的状态,服务器可以立即向他发送消息或发送推送通知。
用户 A 想要向用户 B 发送消息Hello Gainlo。首先将消息发送到聊天服务器。聊天服务器收到该消息,并将确认发送回 A,表示收到该消息。根据该产品,前端可能会在 A 的用户界面中显示单复选标记。情况1:如果 B 在线并连接到聊天服务器,那很好。聊天服务器只是将消息发送给 B.情况2:如果 B 不在线,则聊天服务器向 B 发送推送通知。B 收到该消息,并向聊天服务器发回确认。聊天服务器通知 A,B 接收到消息,并在 A 的用户界面中使用双复选标记进行更新。实时:
HTTP 长连接。简而言之,接收者可以通过长连接发出 HTTP GET 请求,直到聊天服务器返回任何数据才会返回。每个请求将在超时或中断时重新建立。这种方法在响应时间,吞吐量和开销方面有很多优势。显示在线的朋友:
最简单的方法是,一旦用户在线,他会向所有的朋友发送通知。但是,如何评估这个开销?
这在有数百万用户的情况下可能会很多。而这个开销甚至可能比信息开销本身更高。
改进它的一个想法是,减少不必要的请求。
例如,只有当这个用户重新加载页面或发送消息时,我们才发出通知。
换句话说,我们可以将范围限制为“非常活跃的用户”。
或者,用户已经在线五分钟之前,我们不会发送通知。这解决了用户显示在线并立即离开的情况。热点问题:
趋势算法,系统应该能够提供当前流行的主题列表。
基本思路是,对于每个术语而言,如果最近几个小时内的检索量与前 X 天的检索量之比很高,则将其视为一个热门话题。
显然,考虑到每天的大量推文,计算可能开销较大。 在这种情况下,我们可以考虑使用离线流水线。更具体地说,我们可以让多个流水线在离线状态下运行,计算每个术语的比率并将结果输出到某个存储系统。 假设短时间内没有大的差别,流水线可以每隔几小时刷新一次。 所以当用户从前端检查热门话题的时候,我们可以预先计算出这个结果。
如果你只是按照上面的解释计算比例,我很肯定会选择一些非常奇怪的术语。使得分母极小
你可以计算最近几个小时内的检索量/(最近 X 天内的检索量+ 10000)的比值,这样小的检索量就会被稀释。
需要意见领袖吗?—— 用户是否是“平等的”。
有人可能会争辩说,我们不应该给意见领袖更多的权重,因为如果一个话题是趋势,就必须有大量的普通用户在谈论这个话题。这可能是真的。这里的重点是,直到你试一试,你才会知道结果。
个性化:不同的人有不同的品味和兴趣。我们可以根据不同的用户调整趋势列表。根据一些信号,包括他以前的推特,他跟随的人和他喜欢的推文等,计算每个主题和用户之间的相关性分数。然后可以将相关性分数与趋势比率一起使用。另外,位置也应该是一个有价值的信号。我们甚至可以计算每个地点(也许是城市级别)的趋势主题。
缓存系统
缓存系统是目前几乎所有应用中广泛采用的技术。另外,它适用于技术栈的每一层。例如,在网络领域中,缓存用于 DNS 查找,Web 服务器缓存用于频繁的请求。简而言之,缓存系统(可能在内存中)存储常用资源,当下次有人请求相同的资源时,系统可以立即返回。它通过消耗更多的存储空间来提高系统效率。
最常用的缓存系统之一是 LRU(最久未使用)。
如果缓存中存在 A,我们只需立即返回。如果没有,并且缓存具有额外的存储空间,则我们获取资源 A 并返回给客户端。 另外,将 A 插入缓存。如果缓存已满,我们将最久没使用的资源剔除,并将其替换为资源 ALRU 缓存应该支持这些操作:查找,插入和删除。显然,为了实现快速查找,我们需要使用散列。同样的道理,如果我们想要快速插入/删除,链接列表就会出现在你的脑海里。由于我们需要有效地查找最久未使用的项目,所以我们需要按顺序排列队列,栈或有序数组。
双向链表实现的队列来存储所有的资源。此外,还需要一个哈希表,其中资源标识符为键,相应队列节点的地址为值。队列中也需要储存资源 ID,这样从队列中删除资源之后,可以从哈希表中也删除。
换页:RR(随机)、LFU(请求频率)、W-TinyLFU 通过计算时间窗内的频率来解决这个问题。 它也有各种存储优化。
并发:归为经典的读写器问题。
当多个客户端同时尝试更新缓存时,可能会有冲突。例如,两个客户端可能竞争相同的缓存槽,而最后一个更新缓存的客户端将获胜。常见的解决方案是使用锁。缺点是显而易见的 - 它会严重影响性能。
一种方法是将缓存分成多个分片,并为每个分片分配一个锁,这样如果客户端在不同的分片中更新缓存,就不会相互等待。但是,由于热门的条目更有可能被访问,某些分片将比其他碎片锁定得更频繁。
—— 分块思想分布式缓存:当系统达到一定规模时,我们需要将缓存分配给多台机器。
一般的策略是保留一个哈希表,将每个资源映射为相应的机器。nameNode / masterServer
推荐系统
启发式:虽然机器学习(ML)通常用于建立推荐系统,但并不意味着它是唯一的解决方案。
有很多情况下,我们想要更简单的方法,例如,我们可能有很少的数据,或者我们可能想快速建立一个最小的解决方案。在这种情况下,我们可以从一些启发式解决方案开始。事实上,我们可以实现很多黑魔法,来构建简单的推荐系统。例如,根据用户观看的视频,我们可以简单推荐同一作者的视频。我们也可以推荐标题或标签类似的视频。如果我们使用知名度(评论数量,分享数量)作为另一个信号,则这个推荐系统作为一个底线,可以运行得很好。
协同过滤:在谈到推荐系统时,我很难避免提到协同过滤(CF),这是推荐系统中最流行的技术。
简而言之,为了向用户推荐视频,我可以提供类似用户喜欢的视频。例如,如果用户 A 和 B 已经观看了一堆相同的视频,则用户 A 很可能喜欢 B 所喜欢的视频。当然,在这里定义什么是“相似”有很多方式。这可能是两个用户喜欢同一个视频,也可能意味着他们拥有相同的位置。
以上算法被称为基于用户的协同过滤。另一个版本称为基于条目的协作过滤,意思是推荐的视频与用户观看过的视频类似(条目)。特征工程:算法非常普遍。大多数面试官关心的是如何构建针对面试问题的系统。
通常有两种类型的特征 - 显式和隐式特征。显式特征可以是收视率,收藏夹等。在 Youtube 上,它可以是喜欢/共享/订阅行为。隐式特征不太明显。如果用户只观看了几秒钟的视频,可能是一个负面的迹象。给定一个推荐视频的列表,如果用户点击一个而不是另一个,这可能意味着他喜欢点击那个。通常,我们需要深入探讨隐式特征。
喜欢/分享/订阅 - 如上所述,它们是关于用户喜好的强烈信号。观看时间视频标题/标签/类别新鲜度构建机器学习系统的时候,你必须尝试大量的不同特征组合。如果不尝试,你就不会知道哪一个是好的。
耗时:对比类似的用户/视频可能是耗时的,这部分应该在离线流水线中完成。因此,我们可以把整个系统分为在线和离线。
离线部分,所有的用户模型和视频需要存储在分布式系统中
—— 对于大多数机器学习系统来说,使用离线流水线来处理大数据是很常见的,因为你不会期望它在几秒钟内完成。
在线部分,根据用户个人资料和他的行为(如刚刚观看的视频),我们应该能够提供来自离线数据的推荐视频列表。获取比所需更多的视频,然后进行过滤和排序。我们可以过滤与用户观看过的视频无关的视频。然后我们也应该排列这些建议。一些因素应该考虑进来,包括视频流行度(分享/评论/喜欢的数量),新鲜度,质量等方面。随机ID生成器
唯一的用户标识来确定系统中的每个用户。
在某些系统中,你可以从1, 2, 3 ... N持续增加 ID 。在其他系统中,我们可能需要生成一个随机字符串的 ID。
长度固定、排序要求。
单机:递增生成。
第三方:为了将 ID 生成器扩展到多台机器,一种自然的解决方案是维护一个单独的服务器,只负责生成 ID。
—— 然而,这个解决方案的缺点是显而易见的。假设产品如此受欢迎,以至于一秒钟内就可能有大量的注册用户,第三方服务器很快就会成为瓶颈。服务器可能会阻止注册或只是崩溃。每个服务器应该自己能够生成随时间增加的唯一 ID。考虑使用时间戳来生成 ID 应该是很自然的。
我们为每个 ID 生成服务器分配一个服务器 ID,最终的 ID 是时间戳和服务器 ID 的组合。我们还可以在单u200bu200b个服务器上的单个时间戳内允许多个请求。我们可以在每个服务器上保留一个计数器,它表示在当前时间戳里已经生成了多少个 ID。所以最终的 ID 是时间戳,serverID 和计数器的组合。————这个解决方案就是 Twitter 解决问题的方法。他们开放了他们的 ID 生成器,叫Snowflake。
时钟同步:在分布式系统中的系统时钟可能会发生严重偏斜,这可能会导致我们的 ID 生成器提供重复的 ID,或顺序不正确的 ID。 时钟同步不在本次讨论的范围内,但是,了解这个系统中的这个问题对你来说很重要。
k-v存储
最直接的方法是使用散列表来存储键值对。使用哈希表通常意味着你需要将所有内容存储在内存中,这在数据集很大时可能是不可能的。
压缩你的数据。这应该是首先要考虑的事情,而且往往有一堆你可以压缩的东西。例如,你可以存储引用而不是实际的数据。你也可以使用float32而不是float64。另外,使用像位数组(整数)或向量这样的不同的数据表示也是有效的。存储在磁盘中。如果不可能将所有内容都放在内存中,则可以将部分数据存储到磁盘中。为了进一步优化它,你可以把这个系统看作缓存系统。经常访问的数据保存在内存中,其余的在磁盘上。分布式:
如果你想支持大数据,你肯定会实现分布式系统。
将数据分割到多台机器,协调机可以将客户端引导到拥有所请求资源的机器。
好的分片算法应该能够把流量平均平衡到所有的机器。
为了平衡流量,最好确保键是随机分布的。
可用性:
硬件问题更难以保护。最常见的解决方案是冗余。通过建立带有重复资源的机器,我们可以显着减少系统停机时间。如果一台机器每个月有 10% 的几率崩溃,那么使用一台备份机器,我们将两台机器都停机的概率降低到 1%。
分片基本上用来分割数据到多台机器,因为一台机器不能存储太多的数据。冗余是保护系统免于宕机的一种方式。考虑到这一点,如果一台机器不能存储所有的数据,冗余就没有用。
通过引入冗余,我们可以使系统更健壮。但是,一致性是个问题。
第一种方法是将本地副本保存在协调机中。无论何时更新资源,协调机都会保留更新版本的副本。因此,如果更新失败,协调员可以重新进行操作。
另一种方法是提交日志。如果你一直在使用 Git,那么提交日志的概念对你来说应该是相当熟悉的。
最后一种方法是解决读取中的冲突。假设当请求的资源位于 A1,A2 和 A3 时,协调机可以请求所有三台机器。如果数据不同,系统可以即时解决冲突。
吞吐量:为了提高读取吞吐量,常用的方法是总是利用内存。 如果数据存储在每个节点机器的磁盘中,我们可以将其中的一部分移动到内存中。更普遍的想法是使用缓存。
爬虫:
最流行的例子是 Google 使用爬虫从所有网站收集信息。除了搜索引擎之外,新闻网站还需要爬虫来聚合数据源。看来,只要你想聚合大量的信息,你可以考虑使用爬虫。
基本解决方案:在单线程上运行的基本网页爬虫
要抓取单个网页,我们只需要向相应的 URL 发出 HTTP GET 请求,并解析响应数据,这是抓取工具的核心。考虑到这一点,一个基本的网络爬虫可以这样工作:
以包含我们要抓取的所有网站的网址池开始。对于每个 URL,发出 HTTP GET 请求来获取网页内容。解析内容(通常为 HTML)并提取我们想要抓取的潜在网址。添加新的网址到池中,并不断抓取。众所周知,任何系统在扩展后都会面临一系列问题。
抓取频率:对于一些小型网站,他们的服务器很可能无法处理这种频繁的请求。一种方法是遵循每个站点的robot.txt。
去重:在一台机器上,你可以将 URL 池保留在内存中,并删除重复的条目。但是,分布式系统中的事情变得更加复杂。基本上,多个爬虫可以从不同的网页中提取相同的 URL,他们都希望将这个 URL 添加到 URL 池中。当然,多次抓取同一页面是没有意义的。那么我们如何去重复这些网址?
一种常用的方法是使用 Bloom Filter。简而言之,布隆过滤器是一个节省空间的系统,它允许你测试一个元素是否在一个集合中。但是,它可能有误报。换句话说,如果布隆过滤器可以告诉你一个 URL 绝对不在池中,或者可能在池中。
空布隆过滤器是m位(全0)的位数组。还有k个散列函数,将每个元素映射到m位中的一个。所以当我们在布隆过滤器中添加一个新的元素(URL)时,我们将从哈希函数中得到k位,并将它们全部设置为1.因此,当我们检查一个元素的存在时,我们首先得到k位,如果它们中的任何一个不是1,我们立即知道该元素不存在。但是,如果所有的k位都是1,这可能来自其他几个元素的组合。
解析HTML:可能很难使其健壮。你总是会在 HTML 代码中发现奇怪的标记,URL 等,很难涵盖所有的边界情况。
例如,当 HTML 包含非 Unicode 字符时,你可能需要处理编解码问题。另外,当网页包含图片,视频甚至PDF 时,也会造成奇怪的行为。另外,一些网页都像使用 AngularJS 一样通过 Javascript 呈现,你的抓取工具可能无法得到任何内容。
没有银弹,不能为所有的网页做一个完美的,健壮的爬虫。你需要大量的健壮性测试,以确保它能够按预期工作。
有一件事是检测循环。许多网站包含链接,如A->B->C->A,你的爬虫可能会永远运行。
另一个问题是 DNS 查找。当系统扩展到一定的水平时,DNS 查找可能是一个瓶颈,你可能要建立自己的 DNS 服务器。
垃圾回收系统:
电商:
首先,建立一个电子商务网站需要数据库设计,系统可用性,并发性考虑等东西。所有这些在今天的分布式系统中都是非常重要的。
另外,每个人都使用像亚马逊这样的电子商务网站。如果你对周围环境一般很好奇,你应该已经想过这个话题了。三个主要对象:商品(价格,余额,名称,描述和类别),用户和订单(商品 ID,用户 ID,数量,时间戳,状态)。
类别——当然,你可以在 SQL 数据库中创建一个字符串字段,但更好的方法是创建一个类别表,包含类别 ID,名称和其他信息。所以每个商品都可以持有一个类别 ID。
事实上,NoSQL 数据库有时候可以成为电子商务网站的更好选择。
通俗地说,NoSQL 数据库试图将一堆东西存储在一行而不是多个表中。
例如,我们可以将用户已经购买的所有物品存储在用户表的同一行中,而不是单独的订单表。因此,在获取用户的时候,我们不仅可以获取所有的个人信息,还可以获取他的购买历史。对于像 MongoDB 这样的 NoSQL 数据库来说,一个很大的好处就是它支持像这样的庞大数量的“列”。每行可以有大量的列,但不是全部都设置的。这就像将 JSON 对象存储为一行(实际上,MongoDB 使用的是类似的东西 BSON)。因此,我们可以将商品的所有属性(列)存储在一行中,这正是 NoSQL 数据库所擅长的。
并发:只剩下一本书,两个人同时购买。
从操作系统中学到的东西,我们知道锁是保护公共资源最常用的技术。
当 A 获取有关本书的数据时,在这一行上放置一个锁,以便其他人不能访问它。一旦 A 完成购买(减少剩余的数量),我们释放锁,以便 B 可以访问数据。同样的方法应该适用于所有的资源,这可以完全解决这个问题。上述解决方案称为悲观并发控制。尽管它可以防止并发造成的所有冲突,但缺点是开销较大。
乐观锁、悲观锁,这一篇就够了! - SegmentFault 思否
乐观:这里的数据,别想太多,你尽管用,出问题了算我怂,即操作失败后事务回滚、提示。
操作时很乐观,认为操作不会产生并发问题(不会有其他线程对数据进行修改),因此不会上锁。但是在更新时会判断其他线程在这之前有没有对数据进行修改,一般会使用版本号机制或CAS(compare and swap)算法实现。读的多,冲突几率小,乐观锁。
写的多,冲突几率大,悲观锁。可用和一致:分布式系统中实现高可用性,最好的方法是拥有数百或数千个冗余,以便可以容忍许多故障。但是,这里值得注意的是,可用性和一致性是齐头并进的。—— 根据产品的性质,你应该能够做出权衡。
对于电商:延迟和停机时间通常意味着收入的减少,有时这可能是个很大的数字。因此,我们可能更关心可用性而不是一致性。
强一致性:强制所有更新以原子方式,以相同的顺序执行。更具体地说,当有人更新资源时,它将锁定所有服务器,直到所有服务器都持有相同的值(更新后)。因此,如果一个应用建立在强一致性的系统上,则与在单台机器上运行完全一样。显然,这是开销最大的方法,因为不仅锁定是开销较大的,而且它也阻止了系统的每次更新。
弱一致性:提供最低限度的策略。每个冗余都会看到每个更新,但是,它们可能会有不同的顺序。因此,这种方法使得更新操作非常轻量化,但缺点是保证了最低限度的一致性。
最终一致性:在一定的时间内,数据可能不一致。但从长远来看,系统能够解决冲突。
每个冗余可能在特定的时间保存不同版本的数据。所以当客户端读取数据时,可能会得到多个版本。此时,客户端(而不是数据库)负责解决所有冲突并将其更新回服务器
你可能想知道客户端如何解决这些冲突。这主要是一个产品决策。以购物车为例,不丢失任何添加是非常重要的,因为丢失添加意味着收入的减少。所以当面对不同的值时,客户端可以选择物品最多的那个。点击计数器:过去一分钟的访客数量?
对于今天的许多系统,我们需要一个系统,不仅跟踪用户数量,而且实时跟踪不同类型的请求数量。
简单情况:忘记所有的并发问题和可扩展性问题。
简单的解决方案是将所有访客的时间戳存储在数据库中。当有人请求过去一分钟的访客数量时,我们只需查看数据库,并进行过滤和计数。一点点的优化是通过时间戳来排序用户,这样我们就不会扫描整个表。
优化简单情况:
一个简单的想法是只保留过去一分钟的用户,随着时间的推移,我们不断更新列表及其长度。这使我们能够立即获得数量。本质上,我们减少了获取数量的代价,但是必须不断更新列表。空间优化:一个简单的优化是只保留列表中的用户时间戳,而不是用户对象,这可以节省大量的空间,特别是当用户对象很大时。
我们维护了 60 个元素的队列/链表,代表过去的 60 秒。每个元素都存储那一秒的访客数量。所以,每一秒钟,我们从列表中删除最后一个(最早的)元素,并添加一个新的,过去一秒的访客数量。过去一分钟的访客人数是 60 个元素的总和。
—— 多个链表/队列。并发:当两个请求同时更新列表时,可能会有竞争条件。 最初更新列表的请求可能不会最终包含在内。
—— 最常见的解决方案是使用锁来保护列表。 每当有人想要更新列表(通过添加新元素或删除尾部),对列表上锁。 操作完成后,对列表解锁。
—— 在某些时候上锁可能开销很大,并且当并发请求过多时,这个锁可能会阻塞系统并成为性能瓶颈。分布式计数器:
将访问请求平均分配给多台机器。——负载均衡
为了统计这个数量,每台机器独立工作,从过去的一分钟开始统计自己的用户。当我们请求全局数量时,我们只需要把所有的计数器加在一起。
Youtube:
涵盖大部分“主要”组件,包括数据库模型,视频/图像存储,可扩展性,推荐性,安全性等。
最好先从设计的概要描述入手,然后再深入探讨所有细节。
存储和数据模型:实际上,Youtube 从一开始就使用 MySQL 作为主数据库,并且工作得很好。
用户模型,它可以存储在一个表中,包括电子邮件,名称,注册数据,配置文件信息等等。
另一种常见的方法是将用户数据保存在两个表中 - 一个用于与电子邮件,密码,姓名,注册日期等身份验证相关的信息,另一个用于附加的个人信息,如地址,年龄等。作者与视频的关系将是另一张表,将用户 ID 映射到视频 ID。
视频和封面图像存取:
最常用的方法之一是使用 CDN(内容交付网络)。简而言之,CDN 是在多个数据中心部署的全球分布式代理服务器网络。 CDN 的目标是向最终用户提供高可用性和高性能的内容。这是一种第三方网络,许多公司正在 CDN 上存储静态文件。
使用 CDN 的最大好处是,CDN 可以在多个地方复制内容,因此内容离用户更近,跳数更少,内容将通过更友好的网络运行。另外,CDN 负责处理可扩展性等问题,你只需要为服务付费。
—— 在 CDN 中托管流行的视频,而不太流行的视频则按照位置存储在我们自己的服务器中。这有两个好处:
流行的视频由不同地点的大量观众观看,这是 CDN 擅长的。它在多个地方复制内容,以便更可能从接近和友好的网络提供视频。长尾视频通常由特定的人群消费,如果可以预先预测,则可以高效地存储这些内容。数据库扩展:按照需求来。
起始于一台服务器。稍后,你可以演化为一个主机和多个读取从机(主/从模型)。而且在某些时候,你将不得不对数据库进行分区,并采用分片的方法。在谈到缓存时,大多数人的反应是服务器缓存。实际上,前端缓存同样重要。
安全:刷播放量:
——如果一个特定的 IP 发出太多的请求,只是阻止它。
——观看次数较多但参与程度较低的视频非常可疑。Youtube 服务器最初是用 Python 构建的,这允许快速灵活的开发和部署。你可能会注意到许多初创公司选择 Python 作为他们的服务器语言,因为迭代速度要快得多。Python 有时会遇到性能问题,但是有很多 C 的扩展可以让你优化关键部分,这正是 Youtube 的工作原理。要扩展 Web 服务器,你可以简单地拥有多个副本,并在其之上构建一个负载平衡器。服务器主要负责处理用户请求并返回响应。它应该有几个重要的逻辑,其它东西都应该在不同的服务器上构建。例如,建议应该是一个独立的组件,让 Python 服务器从中获取数据。订餐系统
需求:
资源估计:流量、存储、带宽———— (峰谷、扩展性、处理大量并发)
用例图
活动图移动设备可访问性:
推送
支付
国际化?
安全、可用性、
架构:
程序 = 算法 + 数据结构
系统 = 服务 + 数据存储Scenario(场景),Service(服务),Storage(存储),Scale(扩展)。
用户群体
需求:
用例:
资源:
流量:前端显示、后端数据获取池化并发、数据缓存存储CAP
业务逻辑、实体(面向对象)
用户端(web、移动、主机)
负载均衡、应用服务器、
负载均衡、数据库设计、数据存储(种类)、数据缓存(缓存机制)、数据索引、数据备份、数据一致性数据库扩展:
即使我们把数据库放在一个单独的服务器上,也不能存储无限的数据。在某个时候,我们需要扩展数据库。对于这个特定的问题,我们可以通过将数据库分割成像用户数据库,评论数据库等子数据库来进行垂直分割(Partition),或者根据美国用户,欧洲用户等属性进行分割来进行水平分割(Sharding)。架构扩展:
对于数百万用户来说,单个服务器远远不够,由于存储,内存,CPU 限制等问题。这就是为什么当有大量请求时,很常看到服务器崩溃。不要把所有的东西放在一起,最好把整个系统按服务分成小的组件,并把每个组件分开。例如,我们可以将数据库与负载均衡器的 Web 应用(在不同的服务器上)分开。权衡:规范化和反规范化
设置策略阈值来结合多个策略。
CDN
性能优化:SQL、硬件、缓存、架构、死锁、饥饿、索引、内存泄露、耗时操作异步处理
Cache:缓存,万金油,哪里不行优先考虑
Queue:消息队列,常见使用Linkedin的kafka
Asynchronized:批处理+异步,减少系统IO瓶颈
Load Balance: 负载均衡,可以使用一致性hash技术做到尽量少的数据迁移
Parallelization:并行计算,比如MapReduce
Replication:提高可靠性,如HDFS,基于位置感知的多块拷贝
Partition:数据库sharding,通过hash取摸任务队列、并发、吞吐、
系统活跃度:PV、UV、峰谷
消息
日志、权限、session
查找、排序(多个指标)
故障、可用、数据统计挖掘
用户反馈
安全和隐私、用户反馈
向外提供API使用资源
合适优于先进 > 演化优于一步到位 > 简单优于复杂
权衡:比如使用消息队列的好处是解耦和削峰,但是,同样也让系统可用性降低、复杂性提高,同时还会存在一致性问题(消息丢失或者消息未被消费咋办)。
新鲜事系统:Facebook,Twitter,微博,微信朋友圈
时间线:用户首页,时间序列展示。
场景、服务、存储、扩展
先简单后复杂、分析过程更重要、场景:明确需求、设计功能。用户规模访问量读写量,峰值谷值,并发要求。
发布/转发新鲜事;
时间线/新鲜事;
用户关注/取消关注;
登录/注册;
搜索新鲜事;
用户 Profile 的展示与编辑;
上传图像/视频;服务:为需求添加若干服务,相同的服务进行归并。(面向对象设计)
User Service(用户服务):
- 登录
- 注册
News Service(新鲜事服务):
- 发布/转发新鲜事
- 新鲜事
- 时间线
Friendship Service(好友服务):
- 关注好友
- 取消关注
Media Service(媒体服务):
- 上传图片
- 上传视频存储:存储结构、数据库表
SQL 关系型数据库
- 用户信息NoSQL 非关系型数据库
- 新鲜事内容(推文、微博内容)
- 社交图谱文件系统
- 图片/视频表(属性:类型、)。主键、外键、范式。
通常在数据库中存放的密码都经过 hash 之后的扩展:消息获取(push/pull)、优化(×7 缓存、)、热点明星的粉丝快速变化、僵尸粉、
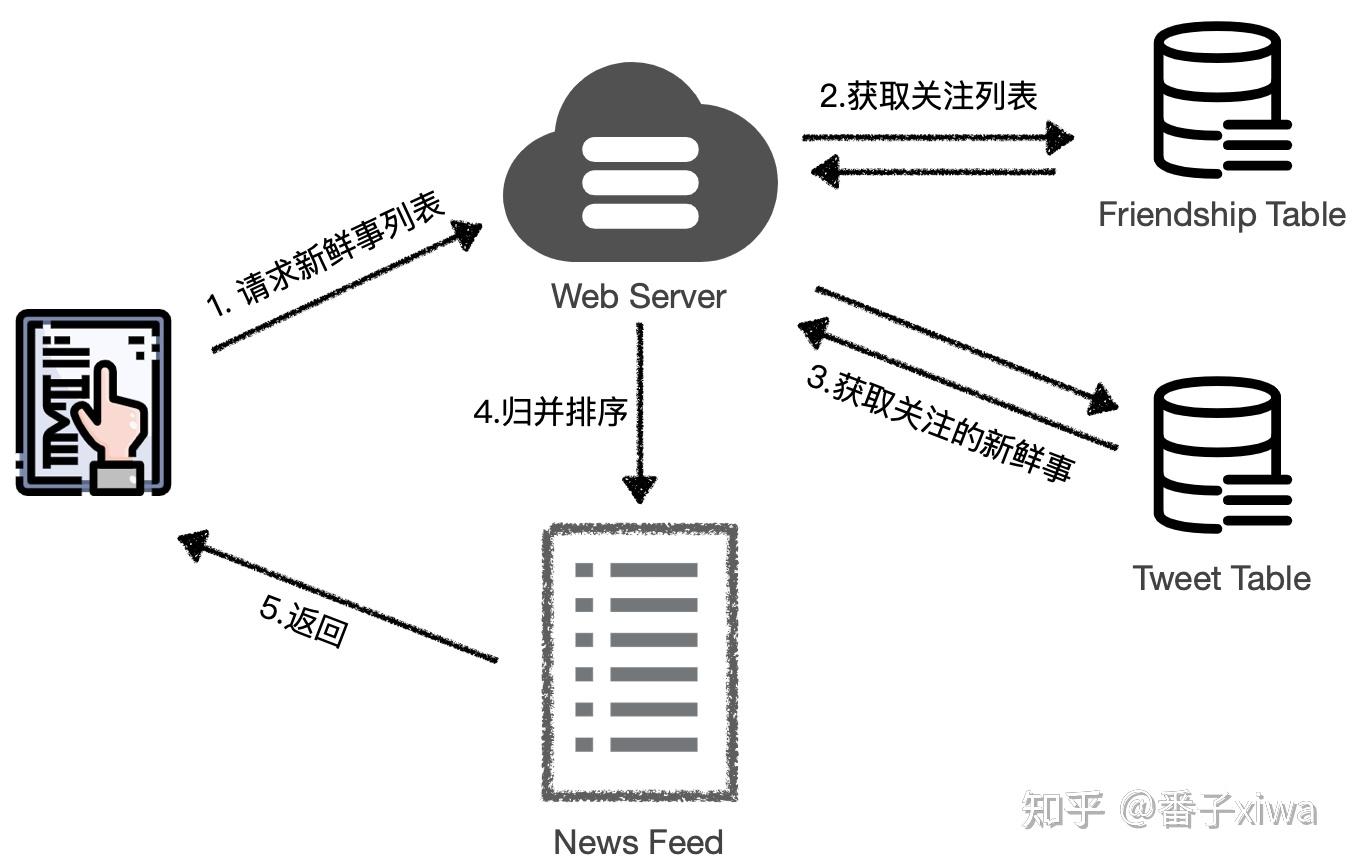
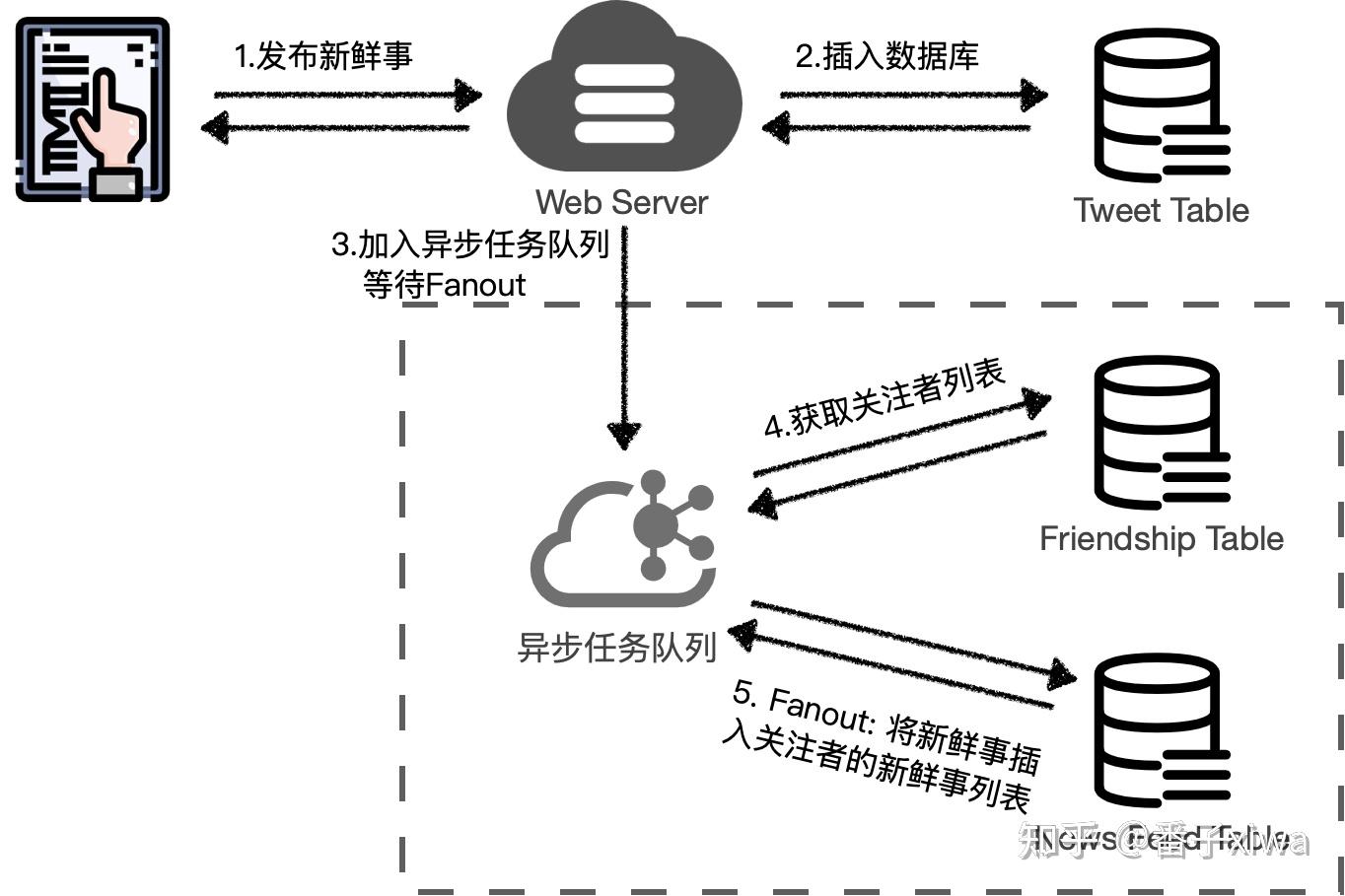

切记不能不坚定想法,在几个方案之间来回摇摆:比如说面试官对你提出的 Pull 模型提了一点质疑,指出了缺陷,然后你的回答又摇摆到了 Push 模型,说“那我们选用 Push 模型就好了”。这是错误的回答方式。
要展现出 tradeoff 的能力:要针对当前系统设计方案的缺陷去做权衡。
秒杀系统
并发量大,应用、数据库都承受不了。另外难控制超卖。
数据用缓存抗,不直接落到数据库。
读写数据和一致性。
终端缓存信息。
如果允许的话,用异步的模式,等缓存都落库之后再返回结果。如果允许的话,增加答题教研等验证措施。像库存这种动态数据会采用被动失效的方式缓存一定时间(一般是数秒),失效后再去Tair缓存拉取最新的数据。加载动画来掩饰性能的落后。
其他业务和技术保障措施:
业务隔离。把秒杀做成一种营销活动,卖家要参加秒杀这种营销活动需要单独报名,从技术上来说,卖家报名后对我们来说就是已知热点,当真正开始时我们可以提前做好预热。系统隔离。系统隔离更多是运行时的隔离,可以通过分组部署的方式和另外 99% 分开。秒杀还申请了单独的域名,目的也是让请求落到不同的集群中。数据隔离。秒杀所调用的数据大部分都是热数据,比如会启用单独 cache 集群或 MySQL 数据库来放热点数据,目前也是不想0.01%的数据影响另外99.99%。短链接生成,这个应该是比较公认的方案了:
分布式ID生成器产生IDID转62进制字符串记录数据库,根据业务要求确定过期时间,可以保留部分永久链接红包系统
像秒杀系统,只不过同一个秒杀的总量不大,但是全局的并发量非常大。
数据库,减库存的时候会抢锁。
请求进行排队,到数据库的时候是串行的,就不涉及抢锁的问题了。不要用缓存顶,涉及到钱,一旦缓存挂掉就完了。
分布式限制流量
固定窗口计数器:按照时间段划分窗口,有一次请求就+1,最为简单的算法,但这个算法有时会让通过请求量允许为限制的两倍。滑动窗口计数器:通过将窗口再细分,并且按照时间“滑动”来解决突破限制的问题,但是时间区间的精度越高,算法所需的空间容量就越大。漏桶:请求类似水滴,先放到桶里,服务的提供方则按照固定的速率从桶里面取出请求并执行。缺陷也很明显,当短时间内有大量的突发请求时,即便此时服务器没有任何负载,每个请求也都得在队列中等待一段时间才能被响应。令牌桶:往桶里面发放令牌,每个请求过来之后拿走一个令牌,然后只处理有令牌的请求。令牌桶满了则多余的令牌会直接丢弃。令牌桶算法既能够将所有的请求平均分布到时间区间内,又能接受服务器能够承受范围内的突发请求,因此是目前使用较为广泛的一种限流算法。推送:push / pull
一般采用推拉结合的方式,用户发送状态之后,
先推送给粉丝里面在线的用户,然后不在线的那部分等到上线的时候再来拉取。美团首页每天会从10000个商家里面推荐50个商家置顶,每个商家有一个权值,你如何来推荐?第二天怎么更新推荐的商家?
—— 堆排序
如何把一个文件快速下发到100w个服务器
边下发,边复制
机房断电
数据一致性、数据恢复、脏数据处理
去中心化
RPC:
1、客户端(Client):服务调用方(服务消费者)
2、客户端存根(Client Stub):存放服务端地址信息,将客户端的请求参数数据信息打包成网络消息,再通过网络传输发送给服务端
3、服务端存根(Server Stub):接收客户端发送过来的请求消息并进行解包,然后再调用本地服务进行处理
4、服务端(Server):服务的真正提供者
1、建立通信
首先要解决通讯的问题:即A机器想要调用B机器,首先得建立起通信连接。
主要是通过在客户端和服务器之间建立TCP连接,远程过程调用的所有交换的数据都在这个连接里传输。连接可以是按需连接,调用结束后就断掉,也可以是长连接,多个远程过程调用共享同一个连接。
2、服务寻址
要解决寻址的问题,也就是说,A服务器上的应用怎么告诉底层的RPC框架,如何连接到B服务器(如主机或IP地址)以及特定的端口,方法的名称名称是什么。
通常情况下我们需要提供B机器(主机名或IP地址)以及特定的端口,然后指定调用的方法或者函数的名称以及入参出参等信息,这样才能完成服务的一个调用。
可靠的寻址方式(主要是提供服务的发现)是RPC的实现基石,比如可以采用redis或者zookeeper来注册服务等等。
3、网络传输
3.1、序列化
当A机器上的应用发起一个RPC调用时,调用方法和其入参等信息需要通过底层的网络协议如TCP传输到B机器,由于网络协议是基于二进制的,所有我们传输的参数数据都需要先进行序列化(Serialize)或者编组(marshal)成二进制的形式才能在网络中进行传输。然后通过寻址操作和网络传输将序列化或者编组之后的二进制数据发送给B机器。
3.2、反序列化
当B机器接收到A机器的应用发来的请求之后,又需要对接收到的参数等信息进行反序列化操作(序列化的逆操作),即将二进制信息恢复为内存中的表达方式,然后再找到对应的方法(寻址的一部分)进行本地调用(一般是通过生成代理Proxy去调用,
通常会有JDK动态代理、CGLIB动态代理、Javassist生成字节码技术等),之后得到调用的返回值。4、服务调用
B机器进行本地调用(通过代理Proxy)之后得到了返回值,此时还需要再把返回值发送回A机器,同样也需要经过序列化操作,然后再经过网络传输将二进制数据发送回A机器,而当A机器接收到这些返回值之后,则再次进行反序列化操作,恢复为内存中的表达方式,最后再交给A机器上的应用进行相关处理(一般是业务逻辑处理操作)。
通常,经过以上四个步骤之后,一次完整的RPC调用算是完成了。
消息处理
点对点(队列)、发布订阅(Topic)
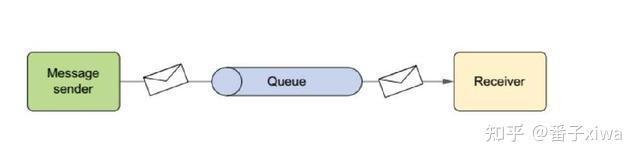

消息的发送端的可靠性:发送端完成操作后一定能将消息成功发送到消息系统。
消息的接收端的可靠性:接收端仅且能够从消息中间件成功消费一次消息。发送端的可靠性
在本地数据建一张消息表,将消息数据与业务数据保存在同一数据库实例里,这样就可以利用本地数据库的事务机制。事务提交成功后,将消息表中的消息转移到消息中间件,若转移消息成功则删除消息表中的数据,否则继续重传。
接收端的可靠性
保证接收端处理消息的业务逻辑具有幂等性:只要具有幂等性,那么消费多少次消息,最后处理的结果都是一样的。
—— 保证消息具有唯一编号,并使用一张日志表来记录已经消费的消息编号。
CAP理论
BASE理论
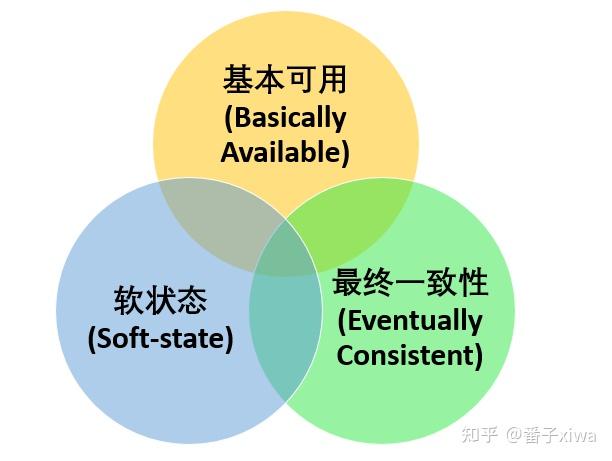
BASE是Basically Available(基本可用)、Soft-state(软状态)和Eventually Consistent(最终一致性)
即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。也就是牺牲数据的一致性来满足系统的高可用性,系统中一部分数据不可用或者不一致时,仍需要保持系统整体“主要可用”。
针对数据库领域,BASE思想的主要实现是对业务数据进行拆分,让不同的数据分布在不同的机器上,以提升系统的可用性,当前主要有以下两种做法:
按功能划分数据库分片(如开源的Mycat、Amoeba等)。基本可用:在出现不可预知故障的时候,允许损失部分可用性。
响应时间上的损失:正常情况下,一个在线搜索引擎需要在0.5秒之内返回给用户相应的查询结果,但由于出现故障,查询结果的响应时间增加了1~2秒系统功能上的损失:正常情况下,在一个电子商务网站上进行购物的时候,消费者几乎能够顺利完成每一笔订单,但是在一些节日大促购物高峰的时候,由于消费者的购物行为激增,为了保护购物系统的稳定性,部分消费者可能会被引导到一个降级页面软状态指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时
最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
负载均衡:
轮询:一共有 6 个客户端产生了 6 个请求,这 6 个请求按 (1, 2, 3, 4, 5, 6) 的顺序发送。最后,(1, 3, 5) 的请求会被发送到服务器 1,(2, 4, 6) 的请求会被发送到服务器 2。

—— 加权轮询
最少连接算法就是将请求发送给当前最少连接数的服务器上。
在最小连接的基础上,根据服务器的性能为每台服务器分配权重,然后根据权重计算出每台服务器能处理的连接数。
把请求随机发送到服务器上。和轮询算法类似,该算法比较适合服务器性能差不多的场景。
实现:
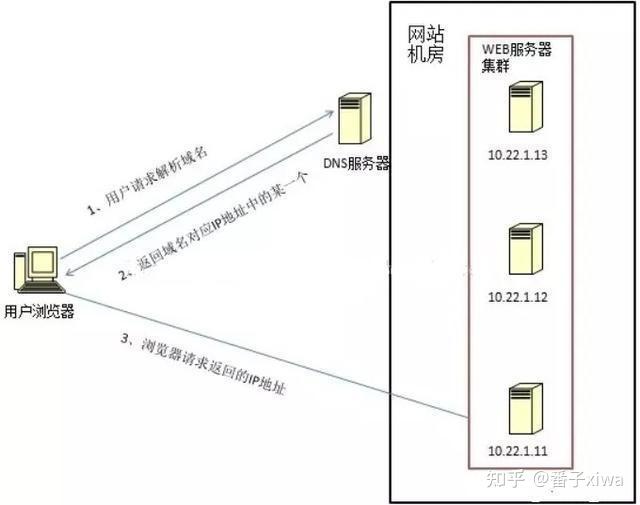
DNS 作为负载均衡器,会根据负载情况返回不同服务器的 IP 地址。
使用 LVS(Linux Virtual Server)这种链路层负载均衡器,根据负载情况修改请求的 MAC 地址。
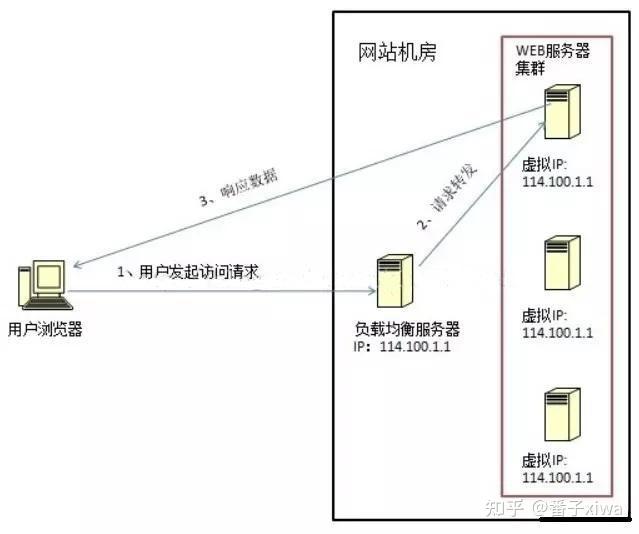
在网络层修改请求的目的 IP 地址。
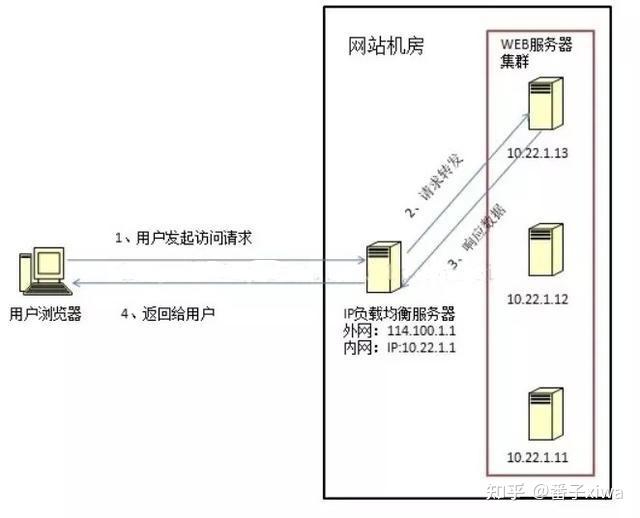
HTTP 重定向负载均衡服务器收到 HTTP 请求之后会返回服务器的地址,并将该地址写入 HTTP 重定向响应中返回给浏览器,浏览器收到后再次发送请求。

反向代理:发生在服务器端,用户不知道发生了代理。
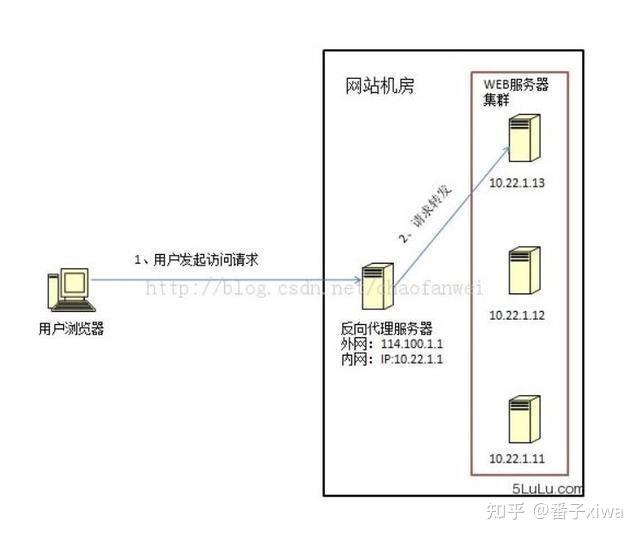
分布式锁:
Java 提供了两种内置的锁的实现,一种是由 JVM 实现的 synchronized 和 JDK 提供的 Lock,当你的应用是单机或者说单进程应用时,可以使用 synchronized 或 Lock 来实现锁。
当应用涉及到多机、多进程共同完成时,那么这时候就需要一个全局锁来实现多个进程之间的同步。
例如一个应用有手机 APP 端和 Web 端,如果在两个客户端同时进行一项操作时,那么就会导致这项操作重复进行。
数据库分布式锁Redis 分布式锁Zookeeper 分布式锁分布式Session:
如果不做任何处理的话,用户将出现频繁登录的现象,比如集群中存在 A、B 两台服务器,用户在第一次访问网站时,Nginx 通过其负载均衡机制将用户请求转发到 A 服务器,这时 A 服务器就会给用户创建一个 Session。当用户第二次发送请求时,Nginx 将其负载均衡到 B 服务器,而这时候 B 服务器并不存在 Session,所以就会将用户踢到登录页面。这将大大降低用户体验度,导致用户的流失,这种情况是项目绝不应该出现的。
粘性 Session
是指将用户锁定到某一个服务器上。缺乏容错性,如果当前访问的服务器发生故障,用户被转移到第二个服务器上时,他的 Session 信息都将失效。服务器Session复制
任何一个服务器上的 Session 发生改变,该节点会把这个 Session 的所有内容序列化,然后广播给所有其它节点,不管其他服务器需不需要 Session,以此来保证 Session 同步。持久化到数据库
数据共享服务器:
Terracotta 的基本原理是对于集群间共享的数据,当在一个节点发生变化的时候,Terracotta 只把变化的部分发送给 Terracotta 服务器,然后由服务器把它转发给真正需要这个数据的节点。它是服务器 Session 复制的优化。相关内容
- 魔兽世界10.0伊斯卡拉海象人声望怎么刷 伊斯卡拉海象人声望速刷攻略
- 魔兽WLK:休闲党必备的专业!可获两个稀有物品,还有奇葩头衔?
- 备战7.0系列之冲垂钓翁声望拿酷炫水黾坐骑
- 魔兽世界7.0四个最难刷的声望 最后一个还有人不知道
- 魔兽世界7.0四个最难刷的声望 最后一个还有人不知道
- 魔兽世界7.0四个最难刷的声望 最后一个还有人不知道
- 《荒野大镖客2》本周线上赛马三倍奖励,多项坐骑打折
- 《荒野大镖客2》登录PC,斗鱼主播开启多样玩法,快速上手看这里
- “液体面包”格瓦斯,有什么来头?有人喝了上瘾,有人却难以下咽
- “液体面包”格瓦斯,有什么来头?有人喝了上瘾,有人却难以下咽
- 新疆最佳卡瓦斯/格瓦斯口感的配方配比,先品尝满意后再谈合作。
- 谷雨前野钓,掌握这3个“经典技巧”,连竿狂拉没难度
